What is AWS Glue?
What is AWS Glue?
AWS Glue is an efficient Extract, Transform and Load (ETL) service built specifically to manage and store data within AWS environments. It allows users to easily manage, transform and load their information through queries as well as share metadata that allows for querying and transformation purposes.
AWS Glue helps businesses organize, locate, move and transform data sets across their organization – simplifying development efforts while making use of data more efficiently. AWS Glue connections provide essential tools for extracting data from multiple sources, including S3, Salesforce and Snowflake.
Furthermore, its flexible scheduler makes job execution possible at specific times or events.
Building a Data Preparation Pipeline with AWS Glue
Building a Data Prep Pipeline with AWS Glue Setting up involves setting up a visual workflow which lets users observe their data transform as each step advances. AWS Glue services such as Data Brew must have access to perform necessary actions; an IAM role must also be created so that AWS Glue services may access and execute them effectively.
After creating the required role, project setup includes provisioning sessions, allocating compute resources and configuring data environments. AWS Glue’s user interface has been carefully constructed to guide users through these steps in a straightforward and user-friendly fashion.
One key aspect of AWS Glue is Data Brew recipes; these contain sequences of transformation steps which can be applied directly to datasets for transformation purposes. Overall, AWS Glue can assist with role creation, project configuration, session setup and provisioning compute resources as well as data preparation processes.
Each component works collaboratively to achieve efficient data transformation with no need for programming code. AWS Glue Data Brew offers an effective means for creating data, with special attention paid to secure access management, visual clarity, and recipe reuse.
Maintain High-Quality Data with AWS Glue Data Quality
AWS Glue’s new feature “AWS Glue Data Quality” enables users to perform quality checks on any dataset generated either via ETL processes (Extract, Transform and Load) or directly imported. This new offering allows organizations and enterprises to ensure high-quality data is being generated or imported through AWS Glue, whether by manually ingestion or ETL processes.
This feature of AWS Glue Data Catalog can be easily accessed directly through its AWS console under “Glue Data Catalog.” Data Quality features enable users to analyze the integrity of their data using customizable rules defined by an open-source definition language called DQ.
With DQ users can define specific queries to create rules which can later be applied, modified, or removed as desired. Data quality rules can be applied to any dataset managed by Glue, including new incoming or transformed ETL workflow data.
To validate an “orders” table for instance, users can select relevant rules using available tools and commands and apply them accordingly. Glue Data Quality offers users a convenient interface that enables quick data access and quality checks, improving overall data reliability and operational efficiency.
Utilising these tools, users can ensure their data meets its required standards to increase data reliability and operational efficiency.
Navigating to AWS Glue Data Catalog
Navigate to the AWS Glue Data Catalog, where you can find the table associated with your data. Once in, locate your table by searching or browsing, click “Athena” at the top to open Athena as a new browser tab and launch AWS Athena console experience.
Select partitions associated with your table within Athena console and verify that at least part of its data is visible. Athena recognizes data in accordance with your query specifications, so use its “Query Editor” tab on the left panel for Athena console to enter partition names that need analysis.
The Query Editor allows users to craft and execute queries tailored to individual partitions, while Athena’s updated interface enables improved usability, making various operations such as running queries or exploring datasets interactively more manageable than before.
Before performing queries, adjust the results settings by accessing your S3 bucket and creating a folder to store Athena query outputs. Save this configuration before returning to Athena console for query execution.
Launch S3 browser, find and select the glue bucket, navigate through its folder structure to access course data and locate Athena results folder.
Save the results and confirm with “OK.”
Next, return to Athena and navigate to the AWS Glue Catalog. In the Customer Databases section, click on the “Preview Table” button to browse and select the required table. This allows you to preview the structure and content of the selected table.
Once the correct table is selected, go back to the Customer Databases tab in Athena and use the “Preview Table” button to confirm the data. You can now proceed to write and execute queries on the selected dataset.
Successful data analysis in Athena involves the proper setup of query result paths, understanding partitioned data, using the Glue Catalog effectively.

AWS Glue Training
Integrating Excel Data Using AWS Glue
To create a database within a spreadsheet, navigate to its “Connections” section and click “Add Connection.” Choose an appropriate database type depending on its purpose – for instance a background spreadsheet setup requires preconfigured databases.
An effective database creation in a spreadsheet environment demands careful planning, an awareness of platform limitations and access to appropriate tools. Success requires understanding both technical requirements as well as any constraints involved with its successful completion.
First step to creating transformation scripts using Glue Data Catalog connection objects: add one. The transformation scripts reference that object within their transformation script.
Next, we explore Glue’s Extract, Transform, Load (ETL) process: Each “Glue Job” comprises of an ETL transformation script with defined data sources and targets as well as job configurations triggered manually or via automated events.
These triggers allow users to easily schedule and oversee job execution. To begin your task, navigate to AWS Glue console and examine its script; AWS Glue automates script creation while managing various job components.
Navigating to the Jobs section by selecting “Go ETL”, clicking “Add Job”, and specifying CSV as input format in order to parse customer data is simple with our console. CSV files simplify the process of feeding structured data to Glue Jobs. They act both as input data sources and templates for producing output datasets tailored specifically for particular tasks.
Understanding how Glue Jobs operate – including their transformation scripts, data mappings and triggers – allows efficient automation of data pipelines as well as creation of robust integration workflows.
Data Extraction and Transformation with AWS Glue Dynamic Frames
To start this process off right, an AWS Glue Dynamic Frame is used to extract customer database and table name customer database information from AWS Glue Data Catalog. After data retrieval is complete, a Dynamic Frame can be used to write it to an S3 location.
Prior to writing the data is transformed in several steps such as
Column renaming
Dropping null fields
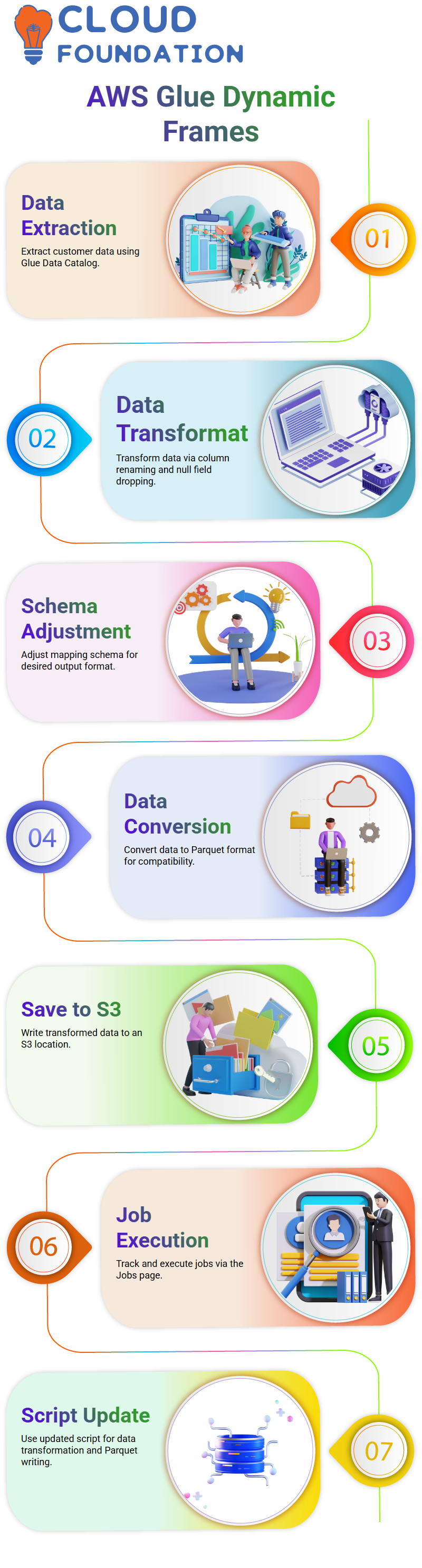
Mapping schema from the Glue catalog are adjusted to conform with desired output format and converted data saved at S3 location. Execution starts by saving and running job or table windows using “Run”, followed by closing any open job/table windows using X button to complete process.
Once a job is selected in the Jobs page, execution begins within minutes and can be tracked from this same page. As is standard practice when saving output as part-K format files for further applications downstream.
To make output compatible and more usable, data must be converted to Parquet format. For this to take effect, an updated script that follows a similar logic is executed: extracting from data catalog, transforming into Parquet files then writing them back onto S3.

AWS Glue Online Training
Automating ETL Workflows and Triggers in AWS Glue
AWS Glue makes this task even simpler through automating ETL Workflows and Triggers that follow this logic. Once this process has completed, data extracted is converted to tables within AWS Glue Data Catalog for storage.
Once your table has been created, use it to run an ETL job until the process completes successfully and your data has been transformed as expected.
Step two involves exploring AWS Glue Triggers which serve to initiate ETL jobs. Triggers can be set to run automatically at regular intervals or upon certain events, providing for automated job execution without manual input from users. Jobs can also be manually started using the console “Run” button.
To create a scheduled trigger, a user selects their trigger type and gives it a name before saving their changes to save a schedule trigger job. Once a schedule has been defined, the user selects an ETL job which should run at that specified time.
Once confirmed by review process and trigger activated, job runs automatically as scheduled according to schedule. This setup ensures ETL jobs run consistently and reliably, streamlining data workflows while decreasing manual monitoring or execution requirements.
Workflow Management Using AWS Glue Start off by creating a temporary directory and altering its schema in order to add a table, while an initial job is also created and set aside; its purpose will be to inspect trigger data database.
As new components are added incrementally, accessing the trigger data database multiple times becomes necessary to maintain data consistency and save time when accessing multiple times is necessary. Time saving techniques such as skipping script execution steps during repeated accesses help achieve this effect.
Setup of a second job was unsuccessful due to an issue in its triggers; therefore, both console and trigger page needed refreshing in order to add and recognize new jobs within system updates. Triggers for events called “go event” were configured.
These triggers are purposefully kept straightforward to ensure an efficient database workflow, using job success as their activation condition. Refreshing this trigger page if there are issues ensures any new jobs will be detected properly and added.
Step 8 is critical in maintaining the integrity of an automation process. AWS Job Events allow administrators to manage workflow dependencies; when one job completes successfully, another job automatically begins based on this trigger event.
Trigger parameters can be set up for automatic chaining between tasks to facilitate these seamless transitions between them, with AWS Glue offering flexible scheduling enabling triggers to activate either at specific time intervals or upon specific events.
To maximize its potential, AWS Glue should be utilized by exploring various combinations of events, triggers and schedules in conjunction with each other in order to develop robust yet adaptable data workflows to do so effectively.
AWS Glue development endpoints provide secure environments for building and testing scripts in development environments, validating job logic before deployment as well as verifying reliability across processes.

AWS Glue Course Price

Vanitha
Author