Data Mining Tutorial
Data mining is the discipline that uses information accumulated via data to perform tasks that might otherwise seem complicated and distant. It draws upon various techniques—classification, clustering, regression, dimensionality reduction, anomaly detection, reinforcement learning, and machine learning—to uncover patterns within data and generalise them to unseen cases.
What is Data mining
Data mining is extracting information from large datasets through machine learning algorithms and analysing large volumes of information to detect patterns and trends.
Data Science aims to extract valuable insights from an abundance of data, including text documents, images, videos, videos with audio commentary, and audio recordings.
Data mining is a practice designed to identify patterns and trends within data. Machine learning algorithms analyse and interpret the data, uncovering potential patterns or trends.

Data mining is an indispensable asset to businesses operating within the information economy. It helps companies to understand and interpret large volumes of data.
Data mining has quickly become a widely utilised process across industries and processes, and businesses need strategies to manage and analyse this burgeoning source of information effectively.
Features of Data Mining
Data mining is a subfield of data science that uses existing information to create predictive models and extract knowledge. It can help uncover insights and patterns hidden among large amounts of information and is thus an invaluable tool.
Businesses must leverage data mining to enhance operations and make informed decisions. Through data mining, organisations can generate more effective solutions that address their unique challenges more quickly and efficiently.
Data mining is expected to gain increasing acceptance due to its ability to yield insightful knowledge into individual behavior and preferences, providing valuable data supporting marketing strategies, supply chain processes and healthcare procedures.
Data Mining offers organisations an effective tool for refining processes, increasing productivity and efficiency, and offering insight into people’s behaviours and preferences. As a result, Data Mining is growing increasingly popular among organisations looking to enhance productivity and efficiency while staying ahead of the competition.
Data mining allows organisations to extract strategic intelligence from extensive unstructured data. By analysing and interpreting this data, organisations can make more informed decisions regarding resource usage and strategically use their available resources.
Data mining can also be utilised to predict the credit card risk for potential new customers based on past information analysed from existing records. By studying and extracting insights from such records, valuable insights can be extracted, allowing the prediction of new clients’ credit risk.
Data mining involves using a database to store and analyse information, including sales figures, customer behavior analysis, and demographic profiles of new customers. It allows businesses to be competitive by more effectively anticipating credit risk while remaining cost-competitive in their market environment.
Keeping such information can ensure your business remains viable in your niche market.Businesses can make educated decisions regarding resource allocation and performance enhancement by carefully analysing this data.
Process of Data Mining
Data mining involves collecting information from diverse sources, such as databases, spreadsheets, and web applications. Once collected, this data is processed using algorithms and data mining techniques to extract meaningful insights, which are stored within databases and analysed and visualised later.
Data mining is part of the knowledge discovery process and involves systematically gathering, processing and analysing information to extract new knowledge from existing datasets.
Data scientists or biologists usually specialise in data mining techniques while data-savvy business analysts also often employ this strategy.
Executives and employees acting as citizen data scientists within organisations possess key components. These elements may include machine learning, statistical analysis, data management tasks or even preparation tasks prior to analysis.
Data mining involves prepping data for analysis by applying machine learning algorithms and other tools. Its main components include machine learning, statistical analysis, data management tasks, and data preparation.
Process of Data Mining
Data mining involves collecting information from diverse sources, such as databases, spreadsheets, and web applications. Once collected, this data is processed using algorithms and data mining techniques to extract meaningful insights, which are stored within databases and analysed and visualised later.
Data mining is part of the knowledge discovery process and involves systematically gathering, processing and analysing information to extract new knowledge from existing datasets. Data scientists or biologists usually specialise in data mining techniques while data-savvy business analysts also often employ this strategy.
Executives and employees acting as citizen data scientists within organisations possess key components. These elements may include machine learning, statistical analysis, data management tasks or even preparation tasks prior to analysis.
Data mining involves prepping data for analysis by applying machine learning algorithms and other tools. Its main components include machine learning, statistical analysis, data management tasks, and data preparation.

Power Apps Training
Transactions include everything from customer sales to flight bookings or advertisements, while data warehouses store this data from multiple sources to facilitate information integration and promote informed decision-making processes.
Data warehouses are multidimensional structures used for storing data. You can query, insert, create or delete information in various ways – making this tool essential to managing and analysing information from multiple sources.
Data warehouses enable users to easily modify, extract, update, and delete information and make informed decisions. Decision-making is another integral feature of data warehouses, allowing the users to make well-informed choices based on their preferences or needs.
Machine learning in Data Mining
Machine learning refers to the algorithms utilised for building prediction models for data mining.
Machine learning (ML) involves creating computer programs that learn from existing data like a human would. People identify patterns within their environment and make predictions based on these. ML programs create computerised versions of this process.
Machine learning aims to detect patterns within data, interpret it accurately, or make predictions. The term refers to algorithms employed within data mining processes to create prediction models already generated from collected information.
Machine learning algorithms help businesses make smarter decisions and anticipate future trends more accurately.
Data science in Data Mining
Data mining is an integral component of data science that utilises methods like statistical analysis and machine learning to uncover patterns in large-scale datasets and reveal new insights.
Data science encompasses collecting, cleaning, analysing, visualising, and modelling information to derive knowledge that can be used in practice.
Data science applies to any data type imaginable – structured, semi-structured, and unstructured. Furthermore, its applications span many disciplines, such as mechanical engineering and cloud architecture.
Data science encompasses many fields, such as statistics, mathematics, data visualisation, programming languages, data mining and machine learning.
You can create your first prediction model using machine learning algorithms by installing WEKA onto your computer and choosing an appropriate version.
Data sets in Data Mining
Datasets are structured collections of related data organised in tables or arrays used for analysis, modeling, and training machine learning algorithms. Their classification involves different analysis approaches, as well as preprocessing steps, modeling steps, and visualisation steps.
Your data structure is integral for saving both time and achieving accurate results. While domain knowledge is integral, most categories remain similar across domains.

Data Mining Online Training
Record data in Data Mining
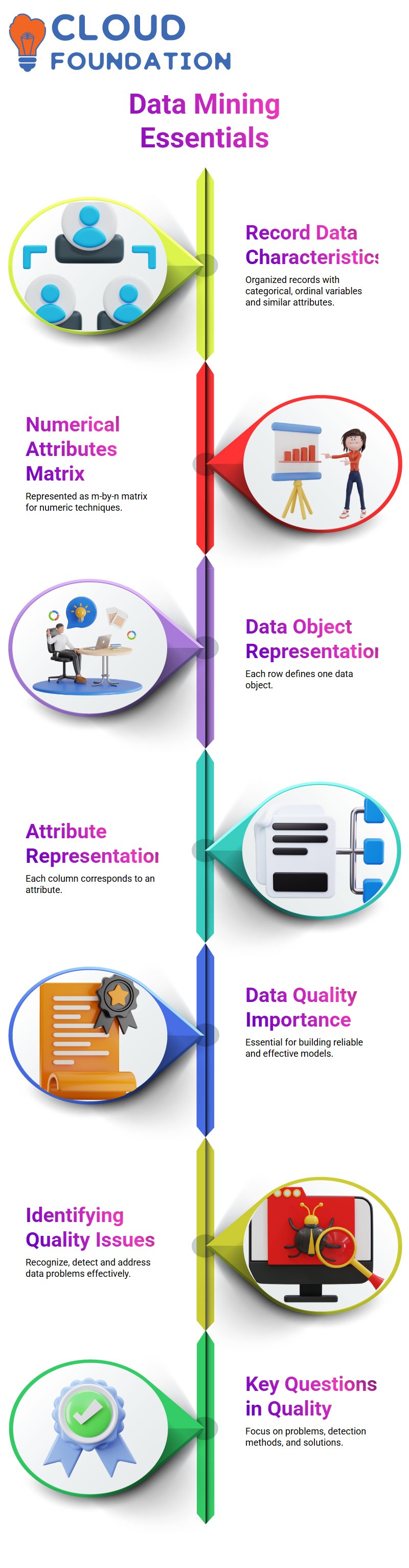
Record Data is an essential dataset encompassing categorical and ordinal variables. It represents an organised collection of records with set attributes containing relevant records with similar characteristics.
If the record data consists solely of numerical attributes, it can be considered an m-by-n matrix with each data object represented by one row and each attribute defined by its corresponding column; this allows numeric techniques, particularly distance-based algorithms, to be effectively utilised.
Data quality in Data Mining
Data quality is vital for novice data scientists in creating effective models that work reliably during production.
Recognising data quality issues and their source is essential for building reliable models that operate effectively in production. When encountering new datasets, three fundamental questions about data quality must be asked: “What problems must be addressed, how can these problems be detected, and what solutions can be proposed? “.
The common kinds of data quality problems
Noise: An invalid signal overlaps valid data, disguising our actual attribute values.
Outliers: Outliers often appear as mere noise at first, yet exhibit characteristics significantly distinct from most objects within your dataset. To address such anomalies, it’s critical to identify which attributes constitute noise and determine effective management solutions.

Missing values: Another prevalent problem is missing values, which result from incomplete data or not having all applicable applications available.
Duplicate data: Unintentional duplicative data creation can arise when gathering information from disparate sources.
Sampling in Data Mining
Sampling refers to selecting an identifiable subset from a larger dataset to reduce computational load while effectively extracting insights and patterns from it.
Sampling is an integral element of data science. When selecting data to process or analyse, sampling plays an essential role. Care must be taken when sampling to consider representation as well as potential sources of noise introduced through missampling.
Sampling has long been used in data science to select, pre-investigate, and analyse relevant information without it being too expensive or time-consuming to acquire all relevant data sets of interest.
There are two types of sampling:
Sampling without replacement
Sampling with replacement
Sampling without replacement: Drawing red balls out of a bag and replacing them as needed are standard methods used in modeling; this approach often produces different mathematical outcomes than is commonly achieved using more standard approaches.
Sampling with replacement: This method involves drawing out one red ball from a bag, exchanging it for another of a different hue, and recording its hue. This produces various mathematical results that may then be implemented across multiple situations.
Conclusion
Data mining is an efficient tool that organisations and businesses use to gain valuable insight from large amounts of data. It employs various methodologies—classification, grouping, and machine learning—to detect hidden patterns or trends and inform informed decision-making.
Data mining has grown increasingly indispensable in today’s data-rich environment, offering endless potential uses in areas as diverse as marketing, healthcare and banking.
As businesses gather more data, machine learning, statistical analysis, and data management are essential for improving processes and increasing output.
Data mining can help businesses go beyond understanding human behavior and anticipating potential outcomes; it can enhance business plans to maximise effectiveness.
Businesses looking to harness data mining’s full benefits must utilise appropriate methods tailored specifically for them and efficiently handle their data while collecting high-quality information. With technology and data science constantly expanding and creating opportunities for growth and innovation in this space, data mining’s future seems promising. It promises growth and innovation as we enter a bright new data science and mining era.

Data Mining Course Price

Vinitha Indhukuri
Author