FHIR HL7 Query Tutorial
Understanding FHIR HL7 Encoding Characters
FHIR HL7 Encoding Characters are an essential aspect of every HL7 message and likely appear in MSH.2 (mandatory segment for trigger events). Today we will dive deeper into them!
Characters play an essential part in structuring HL7 messages. Encoding characters determine how data elements should be separated within message formats for proper interpretation; component separators like the tilde (), ampersand (&), escape sequence and hash symbol (#) all play an essential part.
FHIR HL7 encoding uses escape sequences similar to URL encoding to handle reserved characters in reports, like pipes (|) or carets (). When present in data, specific escape sequences apply if pipes (|) or carets () characters appear, similar to URL encoding.
One useful benefit of escape sequences is using them to highlight critical reports. Within an NT segment, text that requires extra emphasis, such as abnormal medical values or statistics can be formatted bold using special encoding sequences.
FHIR HL7 Encoding Characters provide assistance in message interpretation and assure consistency when transmitting health data transmissions.
Search Techniques in FHIR HL7
Searching patient observations within FHIR HL7 requires using specific identifiers; their types must be searchable when conducting array-based queries and the search list includes them for increased precision of search results.
If available, type parameters can also help narrow results further down.
FHIR HL7 makes searching across an identifier array much simpler; that way it scans each object within it to provide comprehensive and efficient searches.
FHIR HL7 and HL7 v2 Data Conversion
FHIR HL7 is an emerging healthcare standard; however, many institutions still rely on older HL7 v2 messages for interoperability purposes.
Hospitals may request conversion from HL7 v2 to FHIR HL7 messages for interoperability reasons.
When translating from HL7 v2 data to FHIR HL7, maintaining this structure ensures accurate and meaningful transformations.
For instance, names may be formatted using given name/middle name arrangements when translating between formats.
FHIR HL7 Patient Data
Retrieving patient demographics alongside observation data can be essential when working with FHIR HL7, so the underscore include concept allows us to structure queries that combine resources for both patients and observations into one query.
Understanding query syntax is of utmost importance. An under include query follows a structured format consisting of resource name, attribute name and referenced resource name; for instantly in FHIR HL7 systems an observation resource linking directly with patient resources allows doctors direct access to patient details.
This feature can be especially valuable in scenarios in which healthcare providers require both observation results and patient demographics at once, providing more efficient data accessibility in clinical environments.
FHIR HL7 makes updating patient data easy by employing its “PUT” operation, which enables us to specify an existing resource by its ID number and seamlessly modify it.
Our system keeps a version history for each resource to help track changes over time, whether an update or restoration contributes to providing us with an audit trail for accuracy and accountability.
FHIR HL7 Patient Identification
FHIR HL7 also facilitates reverse chaining, which allows searches based on certain observations to find patient records more efficiently.
Imagine being a cardiologist looking for all patients who had heart rate observations without needing their personal details: reverse chaining provides an elegant solution.
Underscore has queries provide a way of retrieving patient resources based on observation references, using specific syntax which includes specifying initiating resource, reference attribute and search criteria in order to achieve comprehensive retrieval through FHIR HL7.
By searching using the LOINC code to search all patients with heart rate observations, cardiologists can efficiently locate relevant patient records without manually filtering data.
Patient Queries in FHIR HL7
At times, we need to narrow our search results. FHIR HL7 makes this easier by restricting patient queries so as to get precise data retrieval results. By applying filter conditions such as filtering by patient name or family identifiers, a more refined dataset emerges.
Searching for an individual patient requires adding search parameters like ‘family=name’ which will narrow your results by only retrieving those which contain that patient name; this eliminates excessive data retrieval, improving performance.
Conditional Queries in FHIR HL7
Conditional queries help maintain data integrity within FHIR HL7. Prior to creating new records, preconditions ensure no duplicate data will be entered into the Clinical Data Repository (CDR), by means of headers such as ‘If-None-Exists’.
Conditional queries provide us with a method for avoiding redundant patient resource creation and are especially effective in maintaining an updated, clean database.

HL7 Training
Data Formats in FHIR HL7
FHIR HL7 supports various data formats, such as JSON, XML and Turtle. While JSON is usually the default structure used when retrieving information through FHIR HL7 requests, its format may be changed in order to retrieve information in different structures.
Developers gain more flexibility in selecting their ideal content delivery format with headers such as ‘Accept: application/fhir+xml’ allowing server providers to more readily meet client demands for access.

FHIR HL7 Response Handling
FHIR HL7 establishes acknowledgment messages, to facilitate proper message flow. A control ID allows us to easily identify which transaction it refers to; key fields within FHIR HL7 like MSA.2 maintain these control IDs so seamless communication occurs.
Error Handling in FHIR HL7
FHIR HL7 allows applications to specify errors within its ERR segment. For instance, if MSH.10 field exceeds its allowed character limit and triggers an error message to help developers address any potential problems quickly and effectively.

How FHIR HL7 Enhances JSON Data Exchange?
FHIR HL7 goes beyond messages: it also facilitates JSON conversion within integration layers. As data moves from HL7 to JSON, its structure transforms into something modern applications can recognize easily.
An application built using JSON receiving FHIR HL7 data must respond accordingly; for instance if status code 200 indicates success then integration engine sends out another acknowledgement letter, reinforcing trust within the system.
FHIR HL7 also ensures that any time an application returns a 400 (bad request), the hospital information system receives notification immediately of this rejection – providing hospitals with an efficient mechanism for quickly tracking data transmission issues.
FHIR HL7 Capability Statement
FHIR HL7′s capability statement provides implementers with vital information about what functions can be provided by servers, informing whether certain patient resource operations such as reading, writing and patching can occur on them.
By retrieving the capability statement through a metadata call, a comprehensive report on supported interactions, resource types, and constraints is generated, providing assurance for seamless integration into an FHIR HL7 server environment.
One key part of FHIR HL7 is the capability statement; this resource lists all available operations, search parameters and server interactions supported. When studying FHIR HL7 exams, understanding its role will prove immensely helpful in passing successfully.
Filtering Data in FHIR HL7
FHIR HL7 provides users with additional filters beyond summary flags for filtering data by specifying attributes like ID or name in its element parameter. Users can quickly retrieve desired information without receiving extraneous data.

HL7 Online Training
Patch Operations in FHIR HL7
FHIR HL7 provides patch operations as an efficient means of updating individual attributes of resources without impacting all resources at once. By switching modes between replace, add, and delete, users can efficiently update their data with minimal effort.
Grouping Resources in FHIR HL7
Bundles in FHIR HL7 provide an effective means of organizing multiple resources into one streamlined entity. From condition resources, practitioner information and transaction requests all the way up to condition monitoring requests – bundling ensures everything runs efficiently within its entirety.
FHIR HL7’s full URL concept plays an essential part in linking resources together in bundles, rather than individual resources being created individually. A bundle allows grouping essential components while still maintaining logical references between resources within it.
FHIR HL7 Acknowledgements
FHIR HL7 plays an indispensable role in healthcare data exchanges. Let’s examine its function within acknowledgements within FHIR HL7, and understand their significance for smooth communications.
Original Mode A hospital transmits data to an integration engine, which responds instantly with an acknowledgement – this immediate feedback keeps systems synced up securely and efficiently, guaranteeing patient data travels efficiently between systems.
FHIR HL7 also permits enhanced acknowledgements that provide deeper communication insights.
Instead of offering either acceptance or rejection statuses alone, integration engines provide feedback through commit accept/reject or commit error statuses as additional layers of feedback.
![]()
Deletion and History Tracking in FHIR HL7
FHIR HL7’s soft delete mechanism means any attempts at resource deletion leave references intact, so before doing so it is imperative that we check for and ensure integrity of linked data before initiating deletion of a resource.
Once a resource is deleted, the system stores a timestamp that allows historical retrieval via the _history endpoint. This ensures that even deleted records may be examined or restored if required.
Summary Flags in FHIR HL7
FHIR HL7 provides an outline summary parameter which makes retrieving patient records more efficiently by filtering essential attributes within patient resources marked with summary flags.
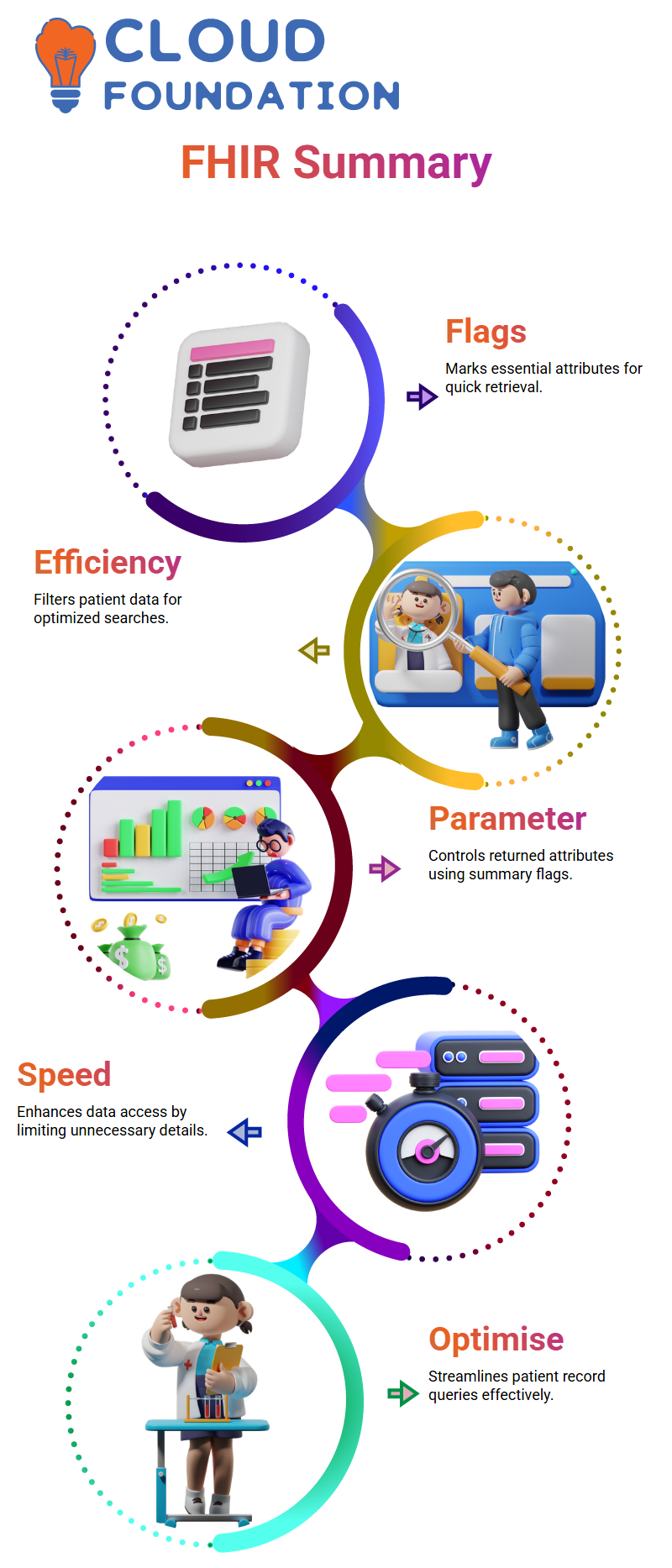
When set to true, only attributes marked as summary flags will be returned, making retrieval faster than ever.
FHIR HL7 Observation Resource
Let’s dive right in to how observation resources function within the FHIR HL7 ecosystem. When retrieving data from CDR, understanding how observation resources interact with patient resources is key for retrieval success.
Observation resources always reference patients, while patients don’t refer back.
Therefore, when querying patients in search of relevant observation data they perform reverse referencing–an understanding this structure is vital when creating queries in FHIR HL7.
Training in FHIR HL7
FHIR HL7 provides us with our initial training. When working with observation resources, it’s crucial that we quickly recognize which attributes support reference data types; not all attributes can be searchable so it’s essential that if an attribute such as ‘subject’ exists as search parameters.
FHIR HL7 uses reference data types; for instance, their subject attribute might not always appear on searchable lists and queries cannot use patient subject as search parameter without it first being indexing as search parameter – making searchability key when structuring queries correctly.

HL7 Course Price

Navya Chandrika
Author