ETL Tutorial
Introduction to ETL
ETL testing is a key aspect of any system when dealing with multiple sources and systems, particularly those of various sources and systems that must communicate.
ETL process development includes using various tools and technologies—from databases and text files to CSV files and SAP Hana types of databases—to carry out ETL processes successfully.
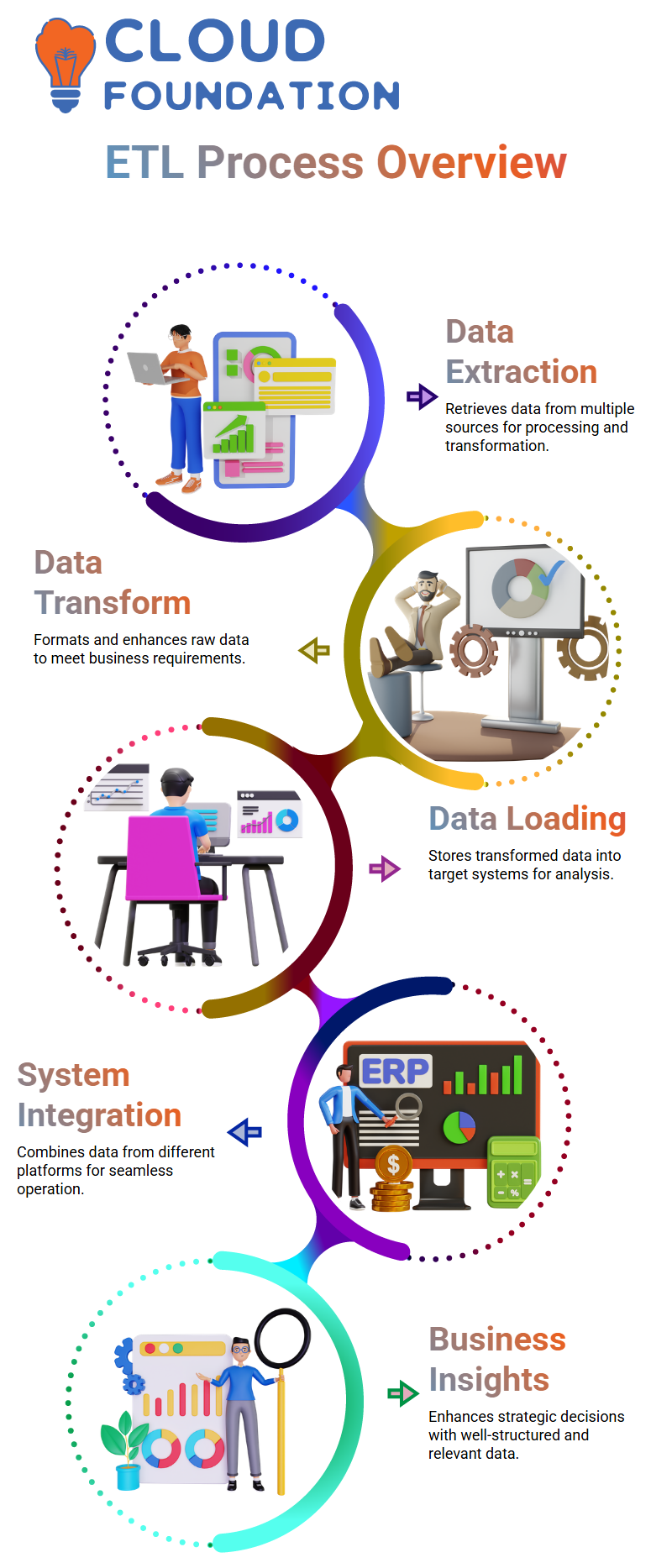
ETL (Extract, Transform, and Load) refers to a process by which data from various source systems is extracted for transformation into its final format for loading into its target systems. This involves performing necessary calculations and transformations to produce usable, meaningful information that meets business requirements.
Data often exists within vast and complicated systems, while decision-making systems only need a subset of that information for analysis and reporting purposes.
ETL ensures only relevant information is extracted and formatted appropriately to meet this need.
This process is flexible enough to integrate data from various systems and ensure proper processing, ultimately leading to smarter strategic decisions and increased system performance.
ETL Process Overview
ETL (Extraction, Transformation, and Loading) comprises three steps of data processing: extraction, transformation, and loading.
Extraction begins by gathering data from multiple sources; transformation subsequently converts this into an organised format suitable for analysis, while loading stores it in its final destination system or warehouse.
Data validation is integral to this process, ensuring that data has been extracted, transformed and loaded correctly.
Validation techniques help confirm that data accuracy remains consistent throughout every stage.
ETL systems are increasingly employed in online environments like Online Transaction Processing (OLTP) and Analytical Processing.
OLTP systems store transactional information, while OLAP systems support reporting and analysis. ETL systems selectively report from these OLAP systems for decision-making, providing users with pertinent details from these reports.
Understanding ETL processes helps optimise data workflows and ensures that information is processed, transformed, and stored for reliable analysis.
Data integration in ETL Testing
Data integration involves moving information from various source systems into one central repository – typically a data warehouse – using ETL (Extract, Transform and Load) tools.
These tools offer an efficient means for combining and prepping data for analysis. Still, they can present additional challenges that require rigorous ETL testing to detect issues like data duplication or truncation.
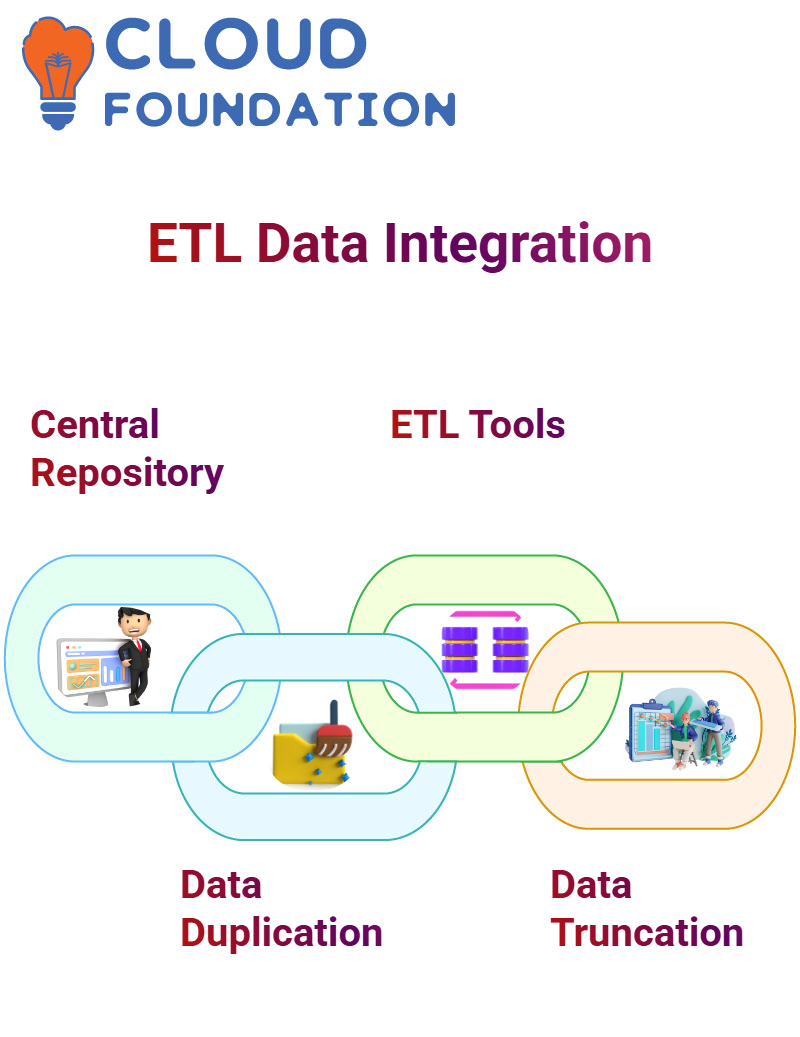
Duplicate records often arise when pulling data from multiple systems or files containing similar records, for instance, Excel sheets, creating duplicate records that compromise quality and accuracy within their target system.
This results in redundant entries on these records, which must eventually be deleted to maintain integrity within this target system.
Data truncation occurs when there’s a discrepancy in data types or length definitions between source and target systems—for instance, when an integer value stored as such exceeds its allowable size in both systems. This leads to lost or corrupted information, which compromises warehouse integrity.
ETL testing should ensure accurate data integration by validating formats, monitoring integration points and verifying data transfers without loss or redundancy.

ETL Training
Data Warehouse Considerations in ETL
As part of creating an ETL data warehouse schema, it’s critical to consider and correct any potential issues during data movement, including truncation, null values, or incomplete records, prior to integration points.
Testing ETL is integral to this process and ensures data validation at multiple integration points.

Aggregated sales figures, such as regional figures, can be loaded as part of an effective data warehouse solution for analytical use.
Sales data from California can be aggregated into cubes for multidimensional analysis, providing more significant regional insights.
Cubes offer an accessible three-dimensional view of data, making it more straightforward for viewers to compare values across time, geography, product, or other dimensions. This increases our capacity to detect trends and patterns effectively.
Regular testing of data quality checks is critical to maintaining accuracy and performance in a data warehouse.
Testing should check for null or truncated values while monitoring for null values that need aggregation/transformation during ETL processes.
Data Handling in ETL Testing
Data is at the core of business intelligence, often broken down along dimensions such as time, location, promotions and sales.
Multidimensional structures allow for flexible analysis and reporting based on various combinations of these attributes.
ETL tools play a pivotal role in prepping data for use, extracting raw information from multiple sources, structuring it accordingly and loading it into data warehouses.
Aggregating by date, region, or product helps increase performance while clarifying reports.
ETL testing ensures that this data is reliable across different reporting levels, accurate, consistent, and aggregated.
Transformations must also be applied correctly so as not to compromise their integrity across these reporting layers.
ETL testing helps ensure data integration and analysis run smoothly by quickly detecting issues like missing values, truncations, or incorrect mappings early in the process. As a result, this leads to improved decision-making across organisations.
This leads to cleaner data integration and reliable analytics, which result in superior decision-making processes and more effective data management across businesses.
Data Migration Process
Data migration involves moving information from one system to another warehouse in an organised fashion.
To start this process, data must be extracted into uniform formats like XML or Excel files before being stored in an intermediate database or staging layer for easy transport and distribution.
Before moving data to its target warehouse, this staging layer must be rigorously validated for accuracy.
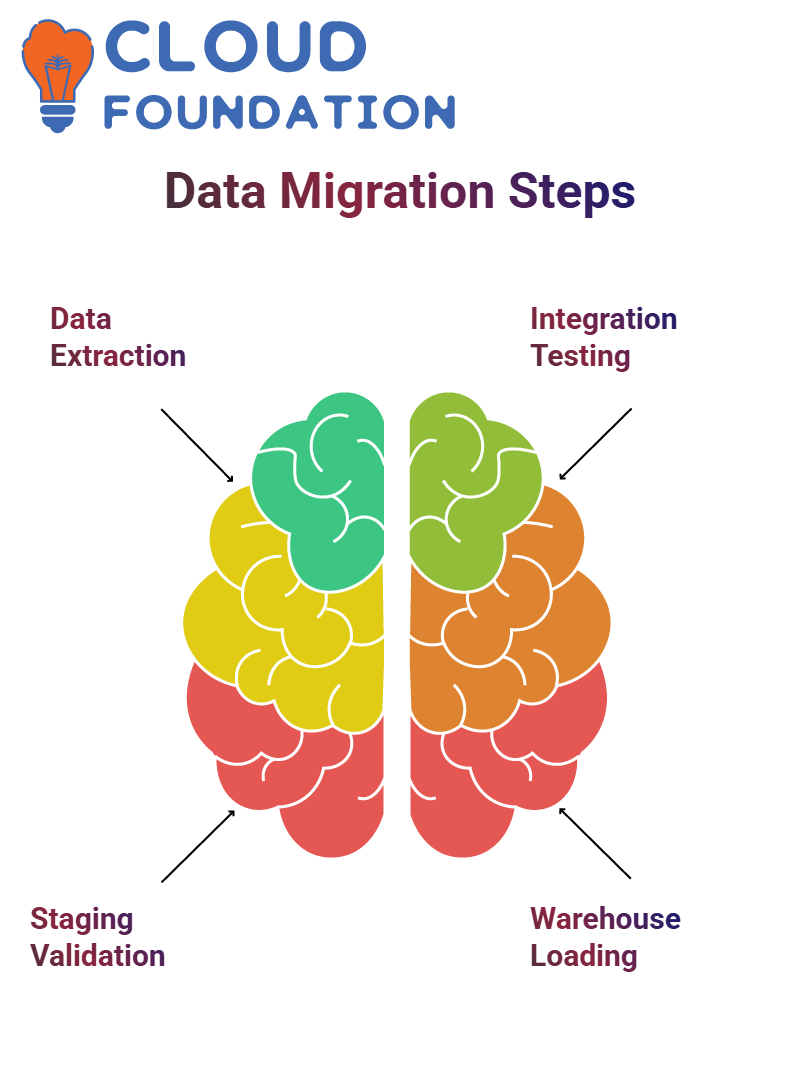
Each stage in this migration process includes testing integration points to ensure that data has been transformed accurately before being loaded into the warehouse.
Multiple test entry points are utilised during migration to ensure data integrity and consistency, and that processing is accurate and compliant with regulatory requirements.
Once verified, the data is loaded into a warehouse for storage with proper access controls to guarantee efficient management and timely retrieval.
This process can be repeated for different data sources to ensure effective management and reliable system integration.
Data Extraction in ETL
Data extraction in ETL refers to retrieving information from various source systems based on their complexity and availability. Each system’s complexity is taken into consideration during the extraction process.
Once an analysis of the source is conducted to identify specific information that needs extracting and its best method(s), data can then be successfully extracted from within ETL itself.
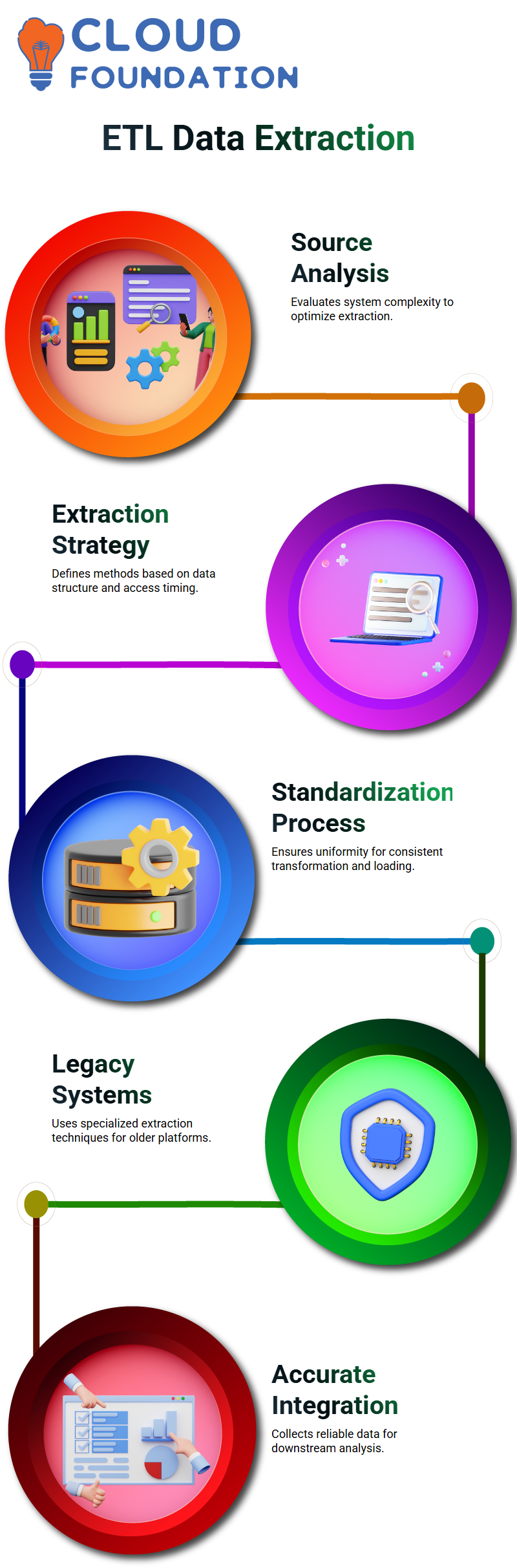
Different systems require various extraction strategies that depend on data structure, system complexity and access timing; legacy mainframe systems often need specific extraction approaches that don’t apply to modern platforms.
The goal should be data standardisation across systems, making transformation and loading as consistent as possible for downstream transformation and analysis.
A well-considered extraction strategy ensures data is collected accurately from every source for further integration and analysis.

ETL Online Training
Data Extraction from Mainframe Systems in ETL
Mainframe systems often do not support tracking changes to data, necessitating extracting and comparing complete datasets before loading them into a data warehouse.
Extraction strategies depend on both system type and source type.

Older systems, such as legacy banking platforms, may present security restrictions and limited connectivity issues that necessitate ETL tools accessing file systems directly to extract data instead of direct system integration.
Effective mainframe data extraction necessitates specific strategies designed to meet system limitations, data formats, and access restrictions, guaranteeing safe data movement and ensuring accurate information transfer.
Importance of Data Coding in ETL
Data Coding is an essential aspect of data management that requires gathering data from various sources, organising it into a standardised code format, and supplementing it with additional sources from outside.
Coding data means storing it across systems while being organised into its final state for later retrieval and use.
This process entails standardising all codes into an easily comparable format; this may mean, for example, changing all ones and zeros to M and F (male/female).
Different transformations are available for new systems, such as importing data from specific source systems, sub-services, or even Global Services like Google.
Google offers an address completion service in America. Users can complete their addresses using their postal codes, helping the data warehouse populate all fields with all-encompassing addresses using this unique technique.
ETL Job Workflow
ETL jobs that routinely poll for files to process and load into data warehouses. Once an input file arrives, an ETL job instantly launches to process this information, either scheduled in advance or in real-time.
Extraction is an integral component of data warehousing to ensure effective data management. It accounts for around 70-80% of transformation through ETL processes, with any remaining transformation occurring via OLAP systems.
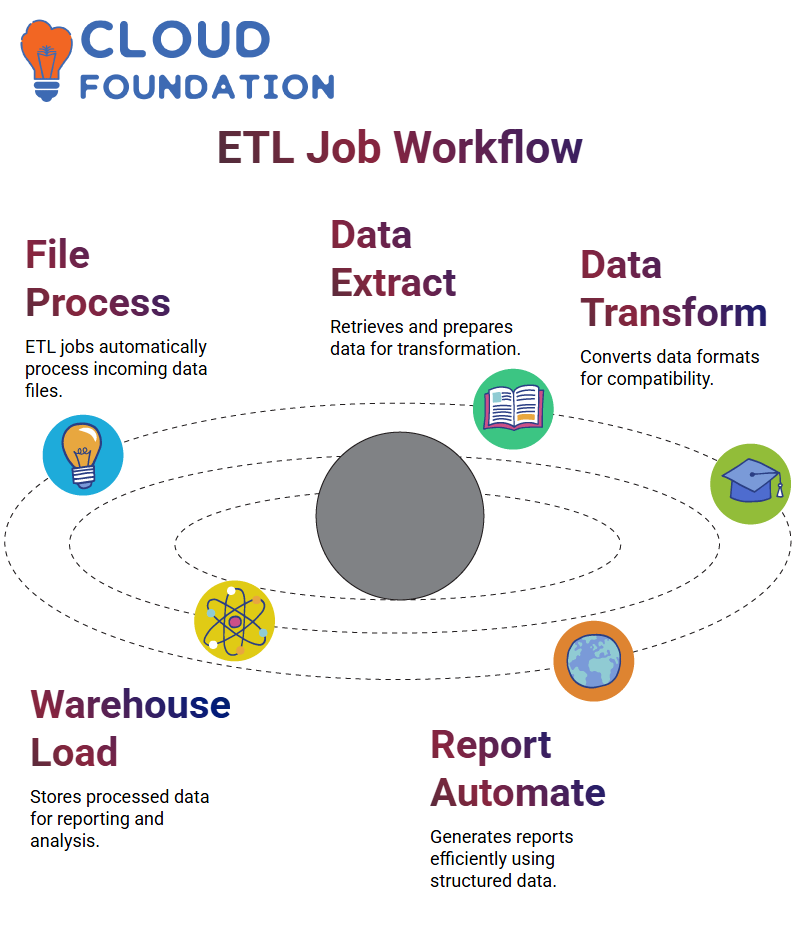
Report generation involves three main steps: extraction, transformation, and loading. Data must be converted from source systems into its desired format during transformation, which may necessitate handling differing date formats across source systems.
Finalising data acquisition involves loading it into a warehouse. This could involve additional transformations for consistency and compatibility purposes. ETL jobs are invaluable in automating data ingestion and transformation for timely report production from various data formats and sources.
Conclusion
ETL (Extract, Transform and Load) is the cornerstone of modern data management, helping organisations turn raw information into actionable insights.
Extracting data across disparate systems requires precision, validation, and careful consideration; loading it into data warehouses requires precision, validation, planning and strategic execution.
ETL testing ensures data integrity, accuracy, and consistency on this journey, whether integrating multiple systems, conducting platform migrations, or working with legacy platforms like mainframes.
Critical components, including data validation, transformation logic, coding standards, and schema design, play a pivotal role in upholding the data quality that fuels business intelligence.
With rapidly evolving technologies and an increased dependence on external services and multidimensional data models, ETL continues to adapt. To ensure successful implementations, efficient data handling techniques, rigorous testing methodologies, and an understanding of source system behaviours are crucial.
By employing carefully planned ETL processes and rigorous testing procedures, organisations can establish reliable data pipelines that support informed decision-making, increase system performance and generate lasting business value.

ETL Course Price

Navya Chandrika
Author