Apache Spark Tutorial
Introduction to Apache Spark
Apache Spark is an invaluable tool for processing large datasets which require multiple computers working together on individual tasks. A proper framework must exist to coordinate work across machines – which Apache Spark does perfectly!
Spark manages and coordinates tasks on data across a cluster of computers with its cluster manager, creating what’s known as an application within Spark for any given job written within it.
Components of Apache Spark
At the core of every Spark application are two essential parts: Driver processes (also referred to as monitor processes or driver agents) and Executor processes.
The former keeps an up-to-date history on Apache Spark applications while responding to user commands or input. The latter then executes their orders.
Analyzing work needed, breaking it into smaller tasks and assigning executor processes is at the heart of Apache Spark applications, to ensure smooth operations while allocating resources according to user input.
The driver process also serves to maintain security measures during execution processes.
To execute code with Apache Spark, one must first establish a Spark session by connecting to its cluster manager with Python or Java code.
Spark sessions can be created in any language and used for simple tasks like generating ranges of numbers by writing just a few lines of code. Data frames similar to MS Excel represent data in rows and columns for easy analysis.
Affine of parallel execution, data must be divided into multiple chunks through partitioning. Transformations provide instructions telling Apache Spark how to modify data for optimal results.

Apache Spark offers several actions for performing transformation block execution. One such action is count, which provides information on how many records make up an array.
Running any one action will execute all transformation block steps and produce final output.
Why Apache Spark
Apache Spark provides an effective solution for big data issues, including training machine learning models or running lengthy SQL queries that take hours to run.
Spark offers data stores to store all data produced from workloads, helping save both money and reduce stress levels when dealing with big data issues.
While Spark provides an impressive distributed file system for use within development or production environments, such a solution often falls short in production systems where more flexibility may be necessary.
Apache Spark is an industry leader when it comes to big data processing technology, providing the ability for data to grow as the complexity does.
Scalability means starting small and adding extra machines as your data expands or complexity grows – ideal for beginning projects that scale with complexity or data growth.
Apache Spark’s syntax is relatively user-friendly and offers several options to get your first cluster running smoothly. In addition, its programming API enables import/export functionality as well as creating code directly within Spark itself.
When choosing a scalable data processing platform, it is key to find one with enough community support and enough popularity that attracts prospective employees with similar skills or those already knowledgeable of its technology.
Apache Spark stands out in this field by efficiently handling large volumes of data on one machine. One key advantage is Apache Spark’s capacity to quickly handle complex data processing tasks efficiently.
Utilizing large-scale clusters enables users to effectively and efficiently allocate resources across a number of machines.
Furthermore, its flexibility facilitates efficient handling of vast amounts of data on one machine while making use of scarce resources effectively and efficiently.

Apache Spark Training
What is Spark
Spark is an accessible browser app designed for monitoring large jobs across many clusters. As its first platform to tackle such an issue, and now considered an essential Next Gen Big Data platform.
Before Spark, there was no real reliable system capable of handling massive data sets for computation purposes.
Spark excels when used on small files, where programming a program to increment counters for every word and store frequency counts in an easily managed Hash Map can be done easily and effortlessly.
On the other hand, when processing large quantities of information (for instance when trying to determine trending words on social networks)
This methodology becomes problematic and more advanced solutions must be employed if dealing with big data (i.e. finding trending terms on internet etc).
Spark can facilitate various tasks, including machine learning, data mining, graph analysis and streaming data services.
Spark is highly scalable, just like other Hadoop-based technologies. Spark can run either on Hadoop itself, its built-in cluster manager, or another cluster, such as Mesos which includes its own cluster manager built-in.
Spark is an impressively efficient technology designed to optimize workflows and work backwards from desired outcomes in order to find the fastest path toward reaching them.
Its speed and performance have become immensely popular, earning this solution praise from Amazon, eBay, NASA, Yahoo among other prominent businesses.
Spark continues its development each year at numerous conferences and user group gatherings. Companies like Amazon, NASA and Yahoo use Spark for real-life problems on massive data sets.
Data Set API
The Data Set API (API) is an innovative technology that empowers users to write programs from desktop computers without dealing with issues that might occur across an enterprise-scale cluster of servers.
Instead, this API enables programmers to focus on solving business issues instead of being consumed by operational issues in such complex multi-node clusters.
This API offers users access to RDD objects for managing distributed data at an intermediate level. Furthermore, users have access to containers which store RDD objects that manage distributed data at a lower level.
Users have direct access to RDD objects when needed and can convert between higher-level containers like data frames and sets and RDDs as needed.
Before beginning their Spark applications, users must understand its core components from an architectural standpoint – specifically data frames sets and RDDs.
Python and Spark libraries
The SQL Library can be seen as being similar to Python Pandas Library in that both libraries facilitate easier interaction and manipulation of data, with one offering greater ease for data manipulation than another. If you wish to utilize Panda syntax directly instead of its API.
Spark requires two modules; Core and SQL; to function successfully, though normally these functions work unobtrusively behind-the-scenes without direct user engagement.
Spark Ml Library was developed specifically to support machine learning tasks, making its usage familiar for those familiar with Scikit-Learn but may require additional resources and hardware resources.
As a data engineer, however, your work could vary significantly from what the data science team requests as they may struggle to achieve the required performance on one machine alone.As another specialty library for working on graph computation with Spark, graph is an indispensable library that assists with this work.

Apache Spark Online Training
How to process and execute the Apache Spark
Apache server processing typically entails several steps, including reading data, converting values and creating spark actions – each essential for efficient data processing and execution.
Beginning by reading data and then manipulating values to transform them (such as from text to dates or back again) there are various transformation techniques such as filters or joining tables which do not result in additional work until called.
Spark actions are commands used to write files, print to screen or collect information and convert the results to list objects for later use in programs.
Before initiating these spark runs must first take place before any actions can take place.
Optimization steps must first be undertaken when creating a Spark graph, which determines which commands must run and in what sequence in order to run most efficiently based on data available.
Size and cluster configurations must also be carefully considered when working with Spark API commands. Otherwise, results might come back like Split which indicates that Apache process hasn’t processed any of your data yet.
When running multiple commands at once, it is vitally important to monitor their execution speed. Without action steps in place yet, Apache could struggle to process data effectively and may fail.
Date lake House
Data lake houses are cloud storage solutions created to store all sorts of information securely while making it easily accessible for multiple users. They ensure data remains safely stored.
Data bricks are an innovative cloud storage service, which empowers users to control their data by employing various means, including resource allocation through data bricks.
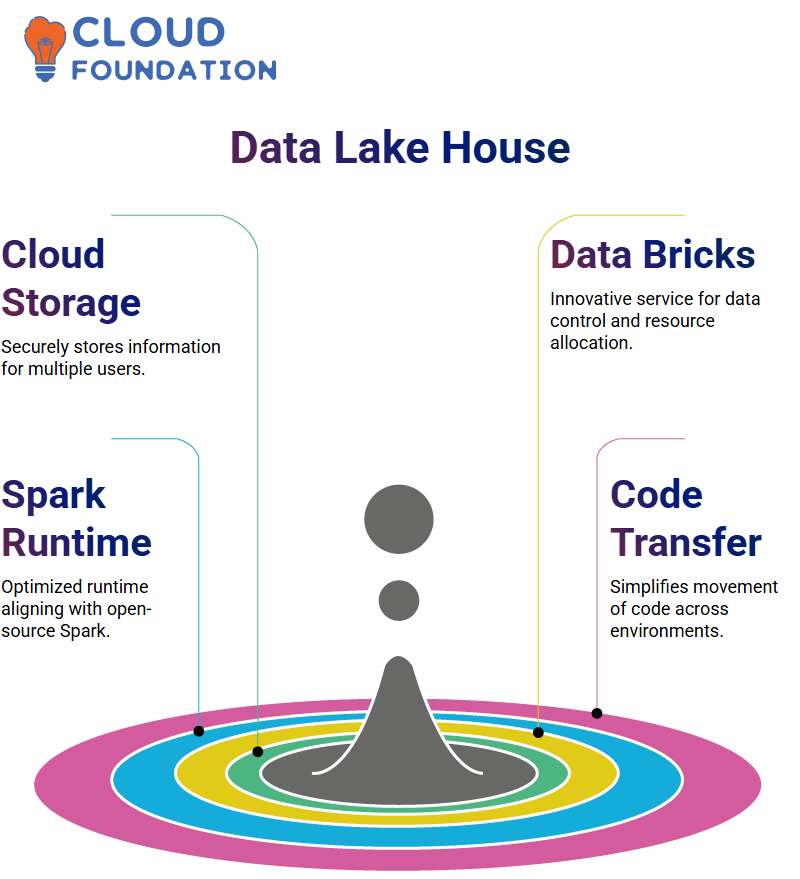
These resources can be seamlessly integrated with other Cloud resources to keep data within its desired environment. Data stored within a secure Cloud environment ensures user data privacy as well as environmental safeguards are met.
Data bricks offer an optimized Apache Spark runtime that aligns well with open-source Spark releases.
Data bricks make code transfer seamless between Spark environments; data can easily move in or out. In addition, Data bricks come equipped with several additional open source tools designed specifically to develop data and AI platforms.
Two years ago, data lake houses first made headlines as an innovative concept to centralise data for multiple purposes – not limited to cloud storage but including use cases such as data lake work.
Use of SQL – Oriented Function
SQL-oriented functions encompass filters, sorting and various brackets used over time in data structures and objects.
Optimizers are responsible for making decisions regarding how best to run functions based on different ways in which we slice and dice data. They take this data into consideration before deciding how best to run them.
Data frame and Spark SQL can often be used interchangeably; however, each has specific meaning: Data frames refer to data stored in databases while Spark SQL refers specifically to Spark databases.
Small groups united toward achieving common objectives may work more closely together towards accomplishing them – for instance reducing errors from queries and improving performance are two such goals that they share in common.
Conclusion
Apache Spark’s outstanding speed, scalability, and user friendliness make it an effective framework for large data processing jobs.
Real-time analytics and machine learning activities benefit greatly from its in-memory processing abilities, support for multiple programming languages, and smooth interface with various data sources.
Spark has proven essential in aiding organizations that want to quickly and meaningfully extract insights from their data quickly, especially as demand for processing large datasets grows rapidly.
Apache Spark stands to remain at the forefront of data analytics with its supportive community and commitment to continual improvements.

Power Platform Course Price

Koppadi Madhavi
Author