What is Hadoop?
Apache Hadoop Is An Open-Source Framework Specifically Designed For Storing And Processing Large Data Sets.
Originally Created For Single Servers To Multiple Machines Offering Local Computation And Storage Capabilities.
Hadoop Is A Platform that Distributes Computing Power and Stores Data on Multiple Computers. Known For Fault Tolerance.
Scalability And Affordability It Is Used Widely Today in Companies that need Data Storage Solutions but lack sufficient processing power in-house.
Organizations Can Utilize Hadoop To Store Structured And Unstructured Data, Process It For Analysis And Gain Competitive Advantage.
Overview, Introduction To Hadoop
Hadoop Is A Free, Open-Source Data Processing Framework That Enables Efficient And Cost-Effective Handling Of Large Amounts Of Data On Commercial Hardware.
It Serves To Provide Efficient Storage And Processing Of Massive Volumes Of Information At An Acceleration Speed.
Composed Of Multiple Components That Provide Distributed Storage (HDFS) And Data Reducing Capabilities (Mapreduce).
Utilizing its Distributed Processing Capabilities, Hadoop Makes It Easier To Process And Analyze Large Amounts Of Data Quickly Than It Would With Traditional Systems.
An Introduction to Hadoop Technologies Hadoop Is A Platform For Distributed Computing That Enables Access To Distributed Storage And Processing Of Data. It Consists Of Multiple Technologies Such As HDFS (Hadoop Distributed File System).
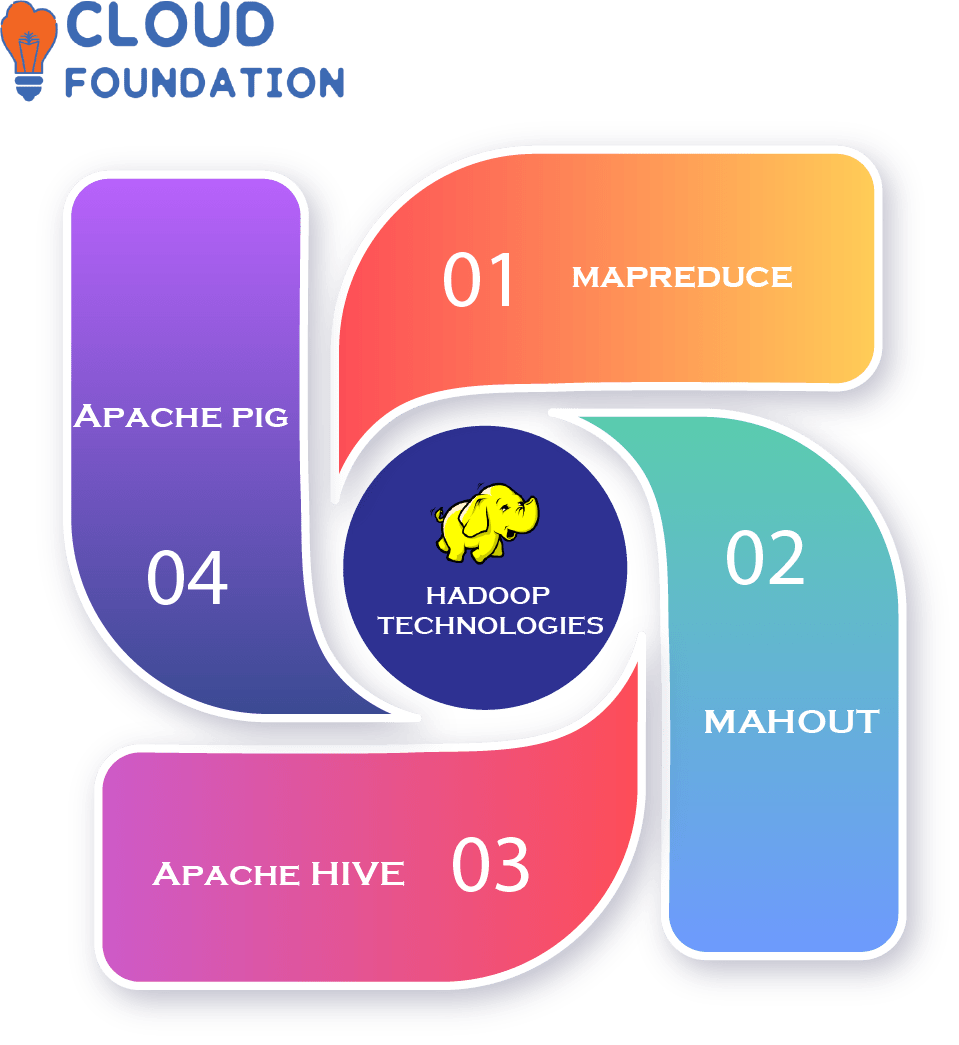
Mapreduce, Mahout, Hive and Pig Are Technologies that Are Intended To Enable Efficient Storage And Processing Of Data On A Large Scale.
Hadoop’s Distributed File System (HDFS) Is Used For Storing Large Amounts Of Information across Multiple Nodes In A Cluster.
HDFS provides Distributed Storage and Access for Large Amounts Of Data.
Definition Hadoop OR Define Hadoop
Hadoop Is An Open-Source Framework Used For Distributed Processing Of Massive Data Sets On Commodity Computer Clusters.
Hadoop Is A Scalable Data Processing Environment That Offers Local Computing And Storage Solutions. Hadoop Is Ideal For Data Mining, Machine Learning, Distributed Computing And Real-Time Analyses.
What Does Hadoop Do And What Is Hadoop Used For?
Hadoop is an open-source software framework written in Java that is used for the storage and processing of large volumes of data.
Based on its Distributed Computing Model, Hadoop is commonly utilized by companies for automating various task automation applications.
Hadoop Enables Users To Analyse Vast Amounts Of Data Rapidly. Traditionally-Supported Systems Require More Time.
As A Common Data Platform For Large Datasets Such As Graphs, Images, Audio And Video. Typically Utilized To Support Applications With Heavy Data Requirements Like Mining And Machine Learning
Hadoop Is Used To Process Natural Language, Image And More. Additionally, It Allows Businesses With An Obsession for Data to Expand And Scale Their Computing Capabilities To Meet Ever Increasing Needs Of Their Businesses.
Uses of Hadoop
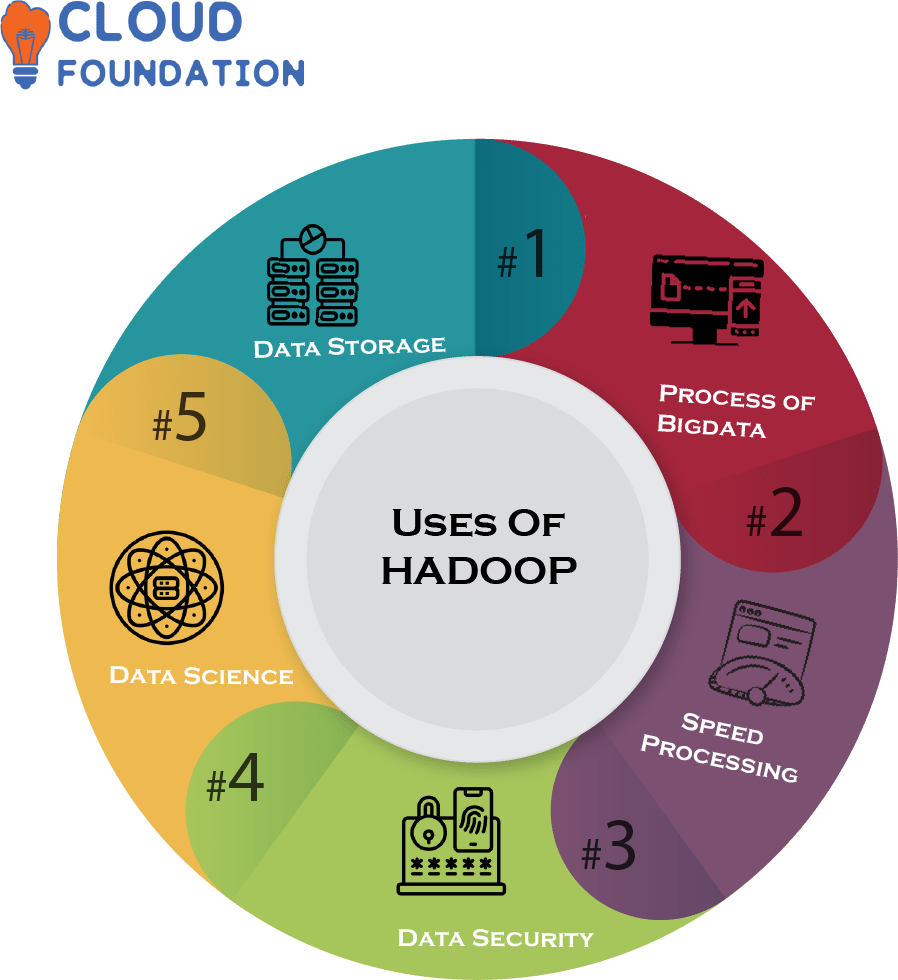
Data Storage: Hadoop Is Primarily Utilized for Large-Scale Data Utilization, As it Allows Storage Of Huge Amounts Of Unstructured Information In Forms Such As Files, Directories, Tables And Blobs.
Process Big Data Quickly with Hadoop: Hadoop can quickly process large datasets. Programming languages like Java, Python, Pig Latin and Hiveql can use its distributed framework for running big data workloads.
Processing Speed: Hadoop Is an Effective Means of Mining Large Amounts Of Data Quickly And Accurately.
Its Distributed Processing Capabilities Allow it To Process Large Amounts Of Information Faster Than Traditional Methods.
Data Security: Hadoop provides data protection through authentication mechanisms, authorization measures and encryption tools.
Data Science: Hadoop can also be used for advanced analytics like predictive modeling and machine learning.
Why Hadoop And What Are The Benefits Of Hadoop?
Hadoop Is A Free and Open-Source Software Platform That Allows For Distributed Storage And Large Scale Data Processing. Users Can Quickly Store And Analyze Vast Amounts Of Information With This Technology Platform; It Has Numerous Advantages that Include Below:
Scalability – Our System Is Highly Scalable, Allowing Users To Add New Nodes As Needed Without Altering Existing Structure.
Fault Tolerance – It Is Built With Fault Tolerance In Mind That Will Enable it to Continue Operating Even If Some Of Its Components Fail
Cost Efficiency – Our System Is Extremely Cost Efficient As It Employs Commodity Hardware That Costs Significantly Less Than Other Solutions.
High Speed Processing – Utilizing Distributed Processing, Our Solution Can Rapidly Process Large Amounts of Data Parallelly.
Flexibility – Hadoop Is An Extremely Flexible System That Allows For Processing Unstructured Data Of All Kinds.
Benefits Of Hadoop
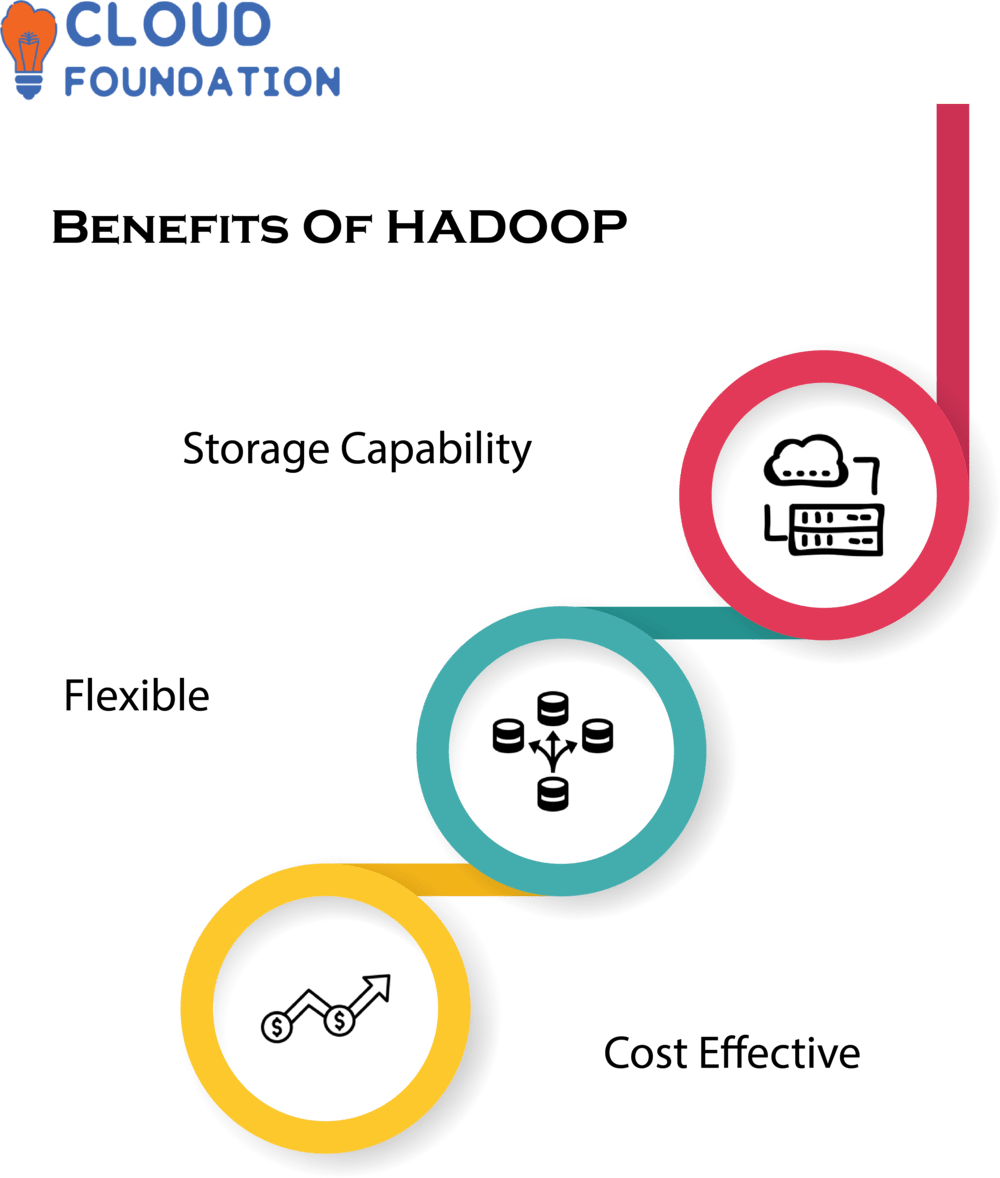
Storage Capability : Hadoop Provides Unlimited Storage Capacity And Can Easily Handle Large Amounts Of Structured, Semi-Structured And Unstructured Information.
HDFS Data Is Distributed and Backed Up Multiple Times.
Scalability: Hadoop Can Scale Horizontally from Single Machine To Multiple Machines for Near Unlimited Processing And Storage Capacity.
Hadoop Protects User Information Through User Authentication, Encryption, User Access Control And Additional Measures Of Security.
Hadoop Is Highly Flexible: With its ability to process and store different types of data from various sources, Hadoop Can Quickly Be Adapted As The Data Architecture Changes And Evolves Over Time.
Cost Effective: Hadoop Is A Cost-Effective Storage Solution, Leveraging Commodity Hardware That’s Far Cheaper Than Proprietary Solutions.
Fault Tolerant: Hadoop Has AnAntifail Architecture That Guarantees Data Is Never Lost Due to Node Failure.
Hadoop Offers High Speed Data Processing Through Parallel Processors and Faster Processing Times. Powered Analysis Tools Such As Predictive Analytics, Data Mining & Machine learning and More…
Hadoop’s Advantages include speedy processing times as it supports parallel processing while offering powerful analysis features including Predictive Analyses.
Data Mining and Machine learning to provide powerful features of analysis that enable advanced applications like Predictive Analytics.
Advantages of Hadoop
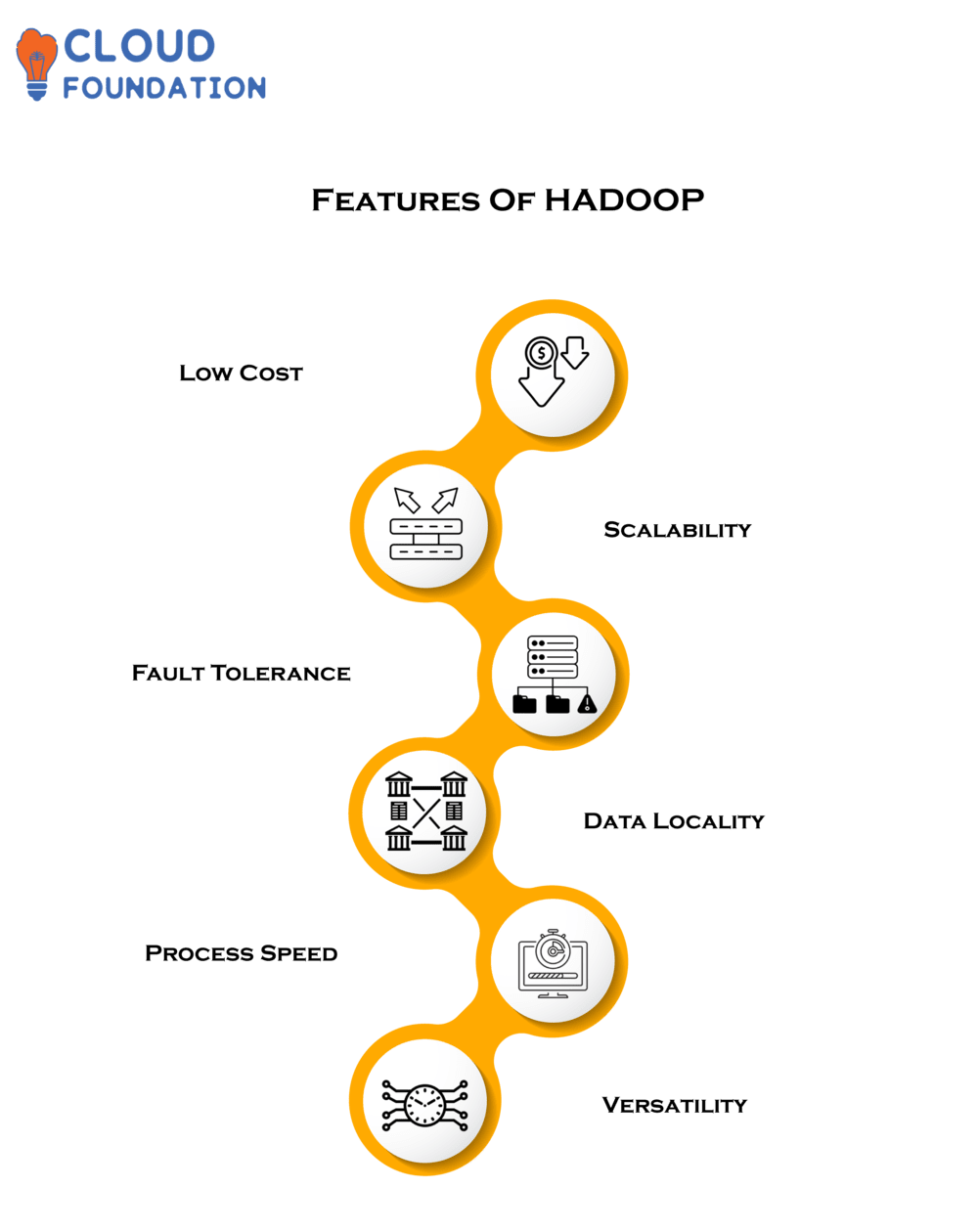
Low Cost: Hadoop Does Not Require Expensive Hardware Infrastructure Or Proprietary Software And This Keeps The Costs Of IT Infrastructure Low.
Scalability: Hadoop Allows Ease Of Scaling Up Or Scaling Down Without Needing New Parts To Substitute For Existing Systems Creating An Extremely Flexible Environment.
Fault Tolerance: Hadoop Is Built With Redundancies To Ensure Reliability And Fault Tolerance, And High Availability Is Essential When Utilizing It For Applications Or Projects.
Data Locality: Hadoop Is Able To Store Data Locally On Its Clusters And Nodes Close To the Source For Faster Processing.
Processing Speed: Hadoop Enables Distributed Processing Of Large Datasets Distributed Over Clusters Of Computers For Speedier And Efficient Processing Of Information.
Versatility: Hadoop Is An Ideal Choice For Handling Different Kinds Of Data From Structured To Unstructured Format, Making It an Adaptable Solution with many applications.
What Is Hadoop Software And How To Use The Hadoop Software?
Hadoop Is An Open-Source Framework For Distributed Storage And Procesing Of Large Data Sets on Commodity-based Cluster Computers.
Hadoop Is A System That Offers Mass Storage For Data Of Any Kind, Enormous Processing Power And The Capacity To Handle Nearly Unlimited Concurrent Tasks Or Jobs.
Ideally Suited To Analyzing Large Amounts Of Information Such As Petabytes Or Larger Volumes, Hadoop Allows For Fast And Efficient Processing And Analyses Of Massive Files Like Text Documents And Audio / Video Files Of Data Of Any Variety Or Size.
Hadoop Software Relies on Two Key Components to Function Properly: the HDFS Distributed Storage System and Mapreduce Processing Engine.
HDFS Provides Component Storage for Distributed Computing while Mapreduce is its processing engine counterpart.
HDFS Is A Cluster-based File System That Stores Information On File Systems Or Object Stores. Mapreduce Is Built Onto The HDFS Platform And Used For Processing.
The Data It Holds in Memory across Multiple Nodes In A Cluster Cluster To Provide Massively Parallel Computing Capabilities For Analyzing It.
Hadoop Provides Support For Applications Such As Analytics, Machine Learning, ETL And Data Mining.
As Part Of Many Big Data Solutions It Also Enables Rapid Processing Of Large Amounts Of Data And Decentralized Applications. How Can Hadoop Help Me Process Data Sets.
How To Use Hadoop?
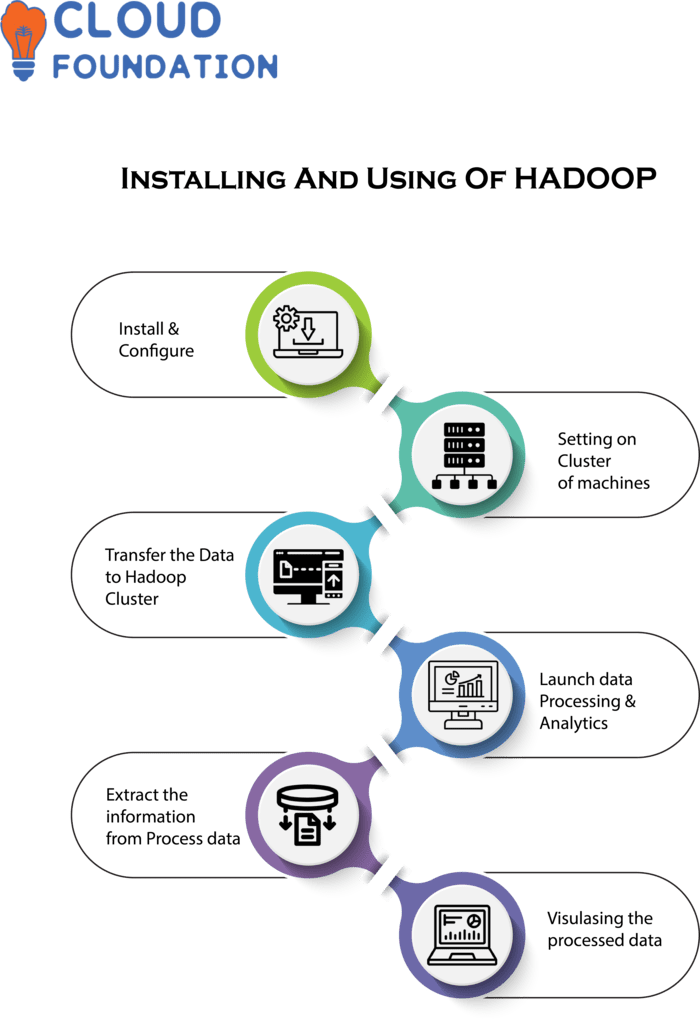
Hadoop Is An Open-Source Software Framework Used for Distributed Storage And Processing Of Large Datasets On Clusters Of Computers.
It Is Widely Employed In Big Data Analytics, Machine Learning And Other Data-Driven Applications.
Install and Configure Hadoop: Start By Downloading, Installing And Setting Up Hadoop On Either A Local Machine Or Cluster Of Machines.
Transfer Data To Hadoop Cluster: Next, transfer your datasets into Hadoop’s Cluster using different file formats such as CSV or JSON files as well as unstructured formats like video and image files.
Launch Data Processing & Analytics: Once Data Is Transferred To Hadoop Cluster, You Can Start Analyzing It By Running Queries And Algorithms Over It.
Additionally Using Mapreduce You Can Also Build Custom Applications To Optimize Operations On It.
Extract Information From Processed Data: Once data processing has taken place, extract and analyze its results for decision making purposes.
Once that step has taken place, this data can then be used to create reports, charts and graphs which help visualize results visually.

Shekar
Author
“Let’s dive into the world of tech imagination with me!”