Sqoop Tutorial
Sqoop is an import tool used for consolidating data from multiple tables into Hadoop clusters as one or multiple tables or sections thereof.
Sqoop also allows users to export data from Hadoop clusters back into relational databases, using SQL plus Hado as an intermediary platform between data sources and Hadoop, providing for an exchange of information between them.
What is Sqoop
“Sqoop” was coined by Cloud computing to refer to an open-by-cloud process and has since evolved into both a command-line tool and single client program.
Sqoop is an accessible data importation and manipulation tool that enables users to import structured data sources such as MySQL Oracle databases. Users can import structured data files such as relational tables into Sqoop to perform actions based on primary keys found within each table.
Sqoop’s functionality and usability make it an indispensable part of the Hadoop ecosystem, helping integrate it with data management systems such as those offered by data warehouses or storage services. A Sqoop command generates map reduce code that transfers the data.
When used together with multiple mappers based on primary key analysis or any other criteria specified within each table.
Sqoop is a tool used for managing tasks within Hadoop. JDBC-compliant, Sqoop can be configured using its command to manage tasks; its connectors provide simple connectivity solutions.
Sqoop can integrate with various databases, from relational to document-based systems and Hadoop-based, via exchange mechanisms like Hive orHBase, that connect these to Sqoop.
Sqoop can interface with various databases, including relational and document-based systems as well as Hado-based Hadoop clusters.
Importing data and Export data in Sqoop
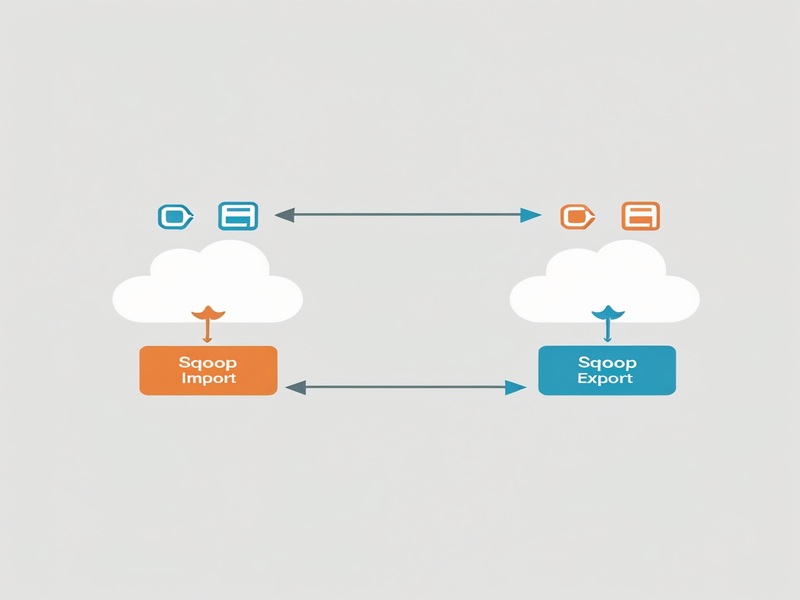
Importing data involves moving it from source systems into Hadoop using Sqoop, while exporting involves moving it out from Hadoop and back into relational environments.
Import and export using Sqoop commands is also possible, working internally as it gathers metadata through its command line interface. Once configured, however, users need only perform two steps – first configuring their task using Sqoop, followed by export/import using it.
Executed via Sqoop is the command to collect metadata.

Sqoop Tutorial Training
Sqoop import and Sqoop export in Sqoop
“Sqoop import” imports all tables, specifying their locations including Warehouse directories. Each table must include at least one column as its primary key value for importation to take effect.
The “Sqoop export” command returns data back to a data store such as MySQL or Hadoop after having imported and analysed it within its database, such as MySQL or Hadoop. This process includes importing it, then analysing it further before returning it back out again via export commands.
Sqoop job
“Sqoop job” refers to a process where repeated commands are executed to import or export data, either on an ongoing schedule or as part of development processes. Sqoop stores these commands as jobs which can be executed anytime without further hassle or development delays.
What steps does Sqoop use to import the “Department” table from SQL to HDFS?
- Select the database where you want to import the data.
- In the “Sqoop Job” command, specify the database location and the table name.
- In the “D-create action” command, specify whether the job is for import or export.
- In the “Export” command, specify the desired output format and parameters.
- In the “Sqoop Job” command, specify the desired output format and parameters
The process of importing data from RDBMS to HDFS and RDBMS to Hive
Following these steps can enable users to effectively integrate data from RDBMSs into HDFS projects and increase performance. Steps include extracting masses from RDBMSs using Sqoop queries; listing tables from RDBMS; using HDFS import features on HDFS for RDBMS import data into target directories.
Import data from RDBMS into HDFS by targeting specific columns with specific data types or conditions; including specific information pertaining to columns and conditions.
What is Hadoop in Sqoop
Hadoop file system is an indispensable way of organizing large data sets efficiently. Based on a map task that maps specific sets to specific mappers for access and opening purposes, Hadoop makes possible parallel processing while offering efficient management solutions for large volumes of information.
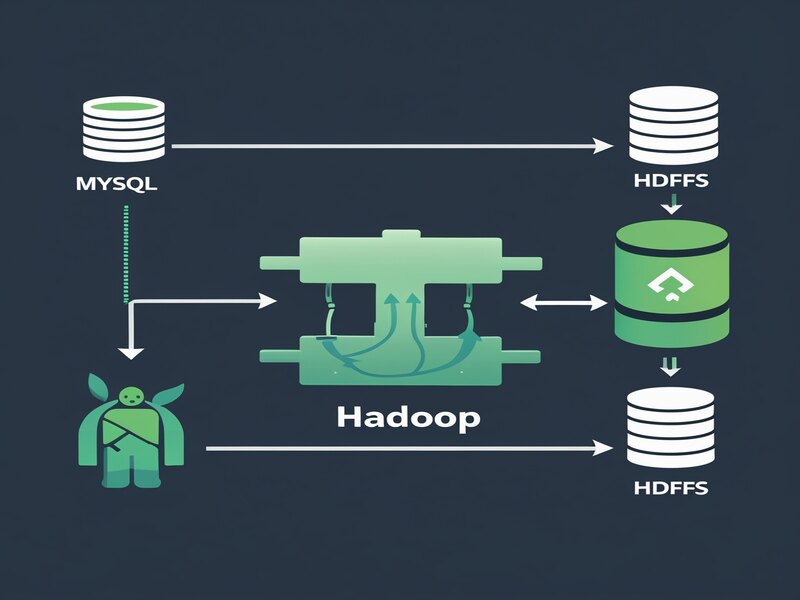
Process of Hadoop
Hadoop processes are fundamental components of Hadoop; tasks loaded onto its database. Of particular relevance in managing data effectively is its Map task.
Hadoop operates through map reduction, an effective technique which reduces the volume of data being processed by mappers in parallel processing; multiple mappers may perform parallel processing through Hadoop itself as one example.
Hbase High provides a target function which identifies specific targets while map tests use Sqoop export command for data export from Hadoop into RDBMS allowing easy import/export using multiple maps.

Sqoop Tutorial Online Training
Hadoop includes a database management system to facilitate collecting metadata and setting up databases such as company archives or company files.
Hadoop also includes a search and query engine that uses Sqoop engine to access various databases for relevant data and submits this to its Hadoop database.
The challenges and benefits of using Hadoop in Sqoop
Hadoop file system plays an integral part in processing large volumes of data from diverse sources, which requires loading it onto its cluster from various sources – an often daunting process due to their diverse nature.
One of Hadoop’s primary challenges lies in its slowness in terms of data using scripts. Writing multiple languages causes issues when creating these scripts interpreting what language the user prefers and making data harder to interpret than ever.
Hadoop has devised an elegant solution: Sqoop allows users to write scripts in any language of their choosing; its architecture also facilitates data import/export operations from various sources.
By understanding Hadoop’s functionality and benefits in managing large volumes of data, one gains a clearer grasp of its benefits and limitations.
Parallelism in Sqoop
Sqoop’s parallelism makes it possible to import SQL query results directly into Hadoop File Systems or Hadoop File Systems (HDFs), offering connectors for several databases – Microsoft SQL Server as well as all major RDBMSs – while protecting against potential performance degradation issues caused by sequential processing.
Sqoop also supports Kerberos computer networks for secure authentication protocols.
Conclusion
Sqoop is a versatile data migration tool designed to quickly transfer information between relational databases and Hadoop’s HDFS filesystem. Users can import their data for storage into HDFS then export back into databases as needed.
Sqoop makes managing large datasets simple with its support for parallel processing and various databases, making managing complex datasets both efficient and straightforward.
Sqoop has many benefits when it comes to data management, from streamlining processes between traditional databases and big data systems to improving integration between them.
Even with its various data source challenges, however, Sqoop provides efficient solution. It simplifies data administration while improving integration.

Sqoop Tutorial Course Price

Vinitha Indhukuri
Author