Spark SQL Tutorial
Introduction to Spark Framework
Spark Framework is an open-source cluster computing and fast processing engine which has become essential to industry for big data processing and analysis. Built around speed, ease-of-use and analytics features, Spark is ideal for large scale dataset projects as it ensures efficient management and data efficiency.
Spark API Algorithms and Components
Spark API offers an assortment of machine-learning algorithms, such as classification, regression, clustering and collaborative filtering, which are intended for implementation using code written from scratch. Furthermore, there’s also an ML library designed specifically for machine learning tasks.
Spark Step, responsible for manipulating graphX files, is another component of Spark API that serves an integral function in its overall implementation. This component allows users to manipulate graphX directly.

Implementation of machine learning algorithms into IoT scenarios such as big data analytics and ML Lib scenarios has the ability to process zero-structured sources, like Hive, while simultaneously processing live streaming data via Park Streaming.
Spark API
Spark is a relational data processing API designed for efficient processing of various structured and non-structured sources, including CSV files, JSON files and K files. Designed to work across resources including Cascading Node databases such as Cassandra and Couchbase that provide schemaRDDs which provide additional RDD storage space efficiently across machines for more effective data analysis. The Spark object may even be processed across machines for rapid data collection.
Spark API’s execution flow revolves around carrying out various tasks, from processing large files and complex data sets, to meeting performance goals with higher performance goals. Spark API offers a high-level abstraction layer which facilitates improved integration between tasks and data types.
Spark SQL
Spark SQL is an exceptional data processing tool designed to enable users to process structured information from various sources with defined schema. Each Rho object represents one record; Park SQL allows users to query this data using this mechanism.
External tools, including JDBC and ODBC database connectors, may be utilized to connect Spark SQL. Furthermore, these external tools may also help integrate it with business intelligence (BI) tools like Tableau.
Spark SQL’s foundational abstraction, the DataFrame, allows users to organize data in multiple columns for access and manipulation in different ways.
Spark SQL architecture
Spark SQL is an open-source database management system which stores and retrieves information from multiple sources – CSV files, JSON strings, or JDBC formats are supported – quickly and effortlessly.
Designed to be easy for its users and administrators alike to maintain, with features like user-defined data registration (UDF) registration as well as creating data frames using different APIs available within it.
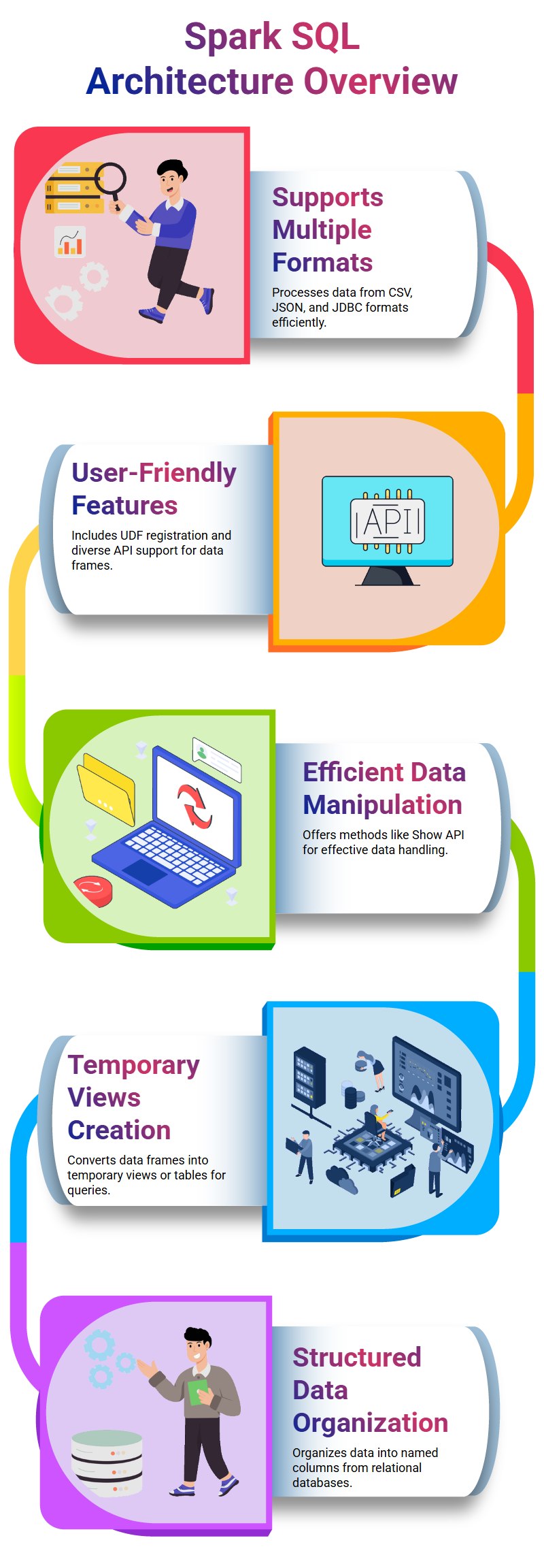
Created using various formats including CSV, JSON and JDBC data sources API’s, creating a data frame involves gathering its components together before being transformed using data source API into its final form.
When developing such structures it’s imperative that creators consider both their database’s specific requirements as well as those being addressed when building out data frames.
Spark SQL architecture also offers various methods for accessing and manipulating data, including show API to retrieve output and source API to retrieve source. As such, Spark SQL architecture serves as an all-inclusive solution for securely and efficiently storing information.

Spark SQL Training
Challenges and Benefits of Spark SQL
Spark SQL can bring several challenges and benefits when used for data analysis, from converting an input data frame into 2DFS format and creating temporary views or tables, through to passing up our SQL statements with SparkSQL for evaluation of performance of temporary views created within 2DFS files.
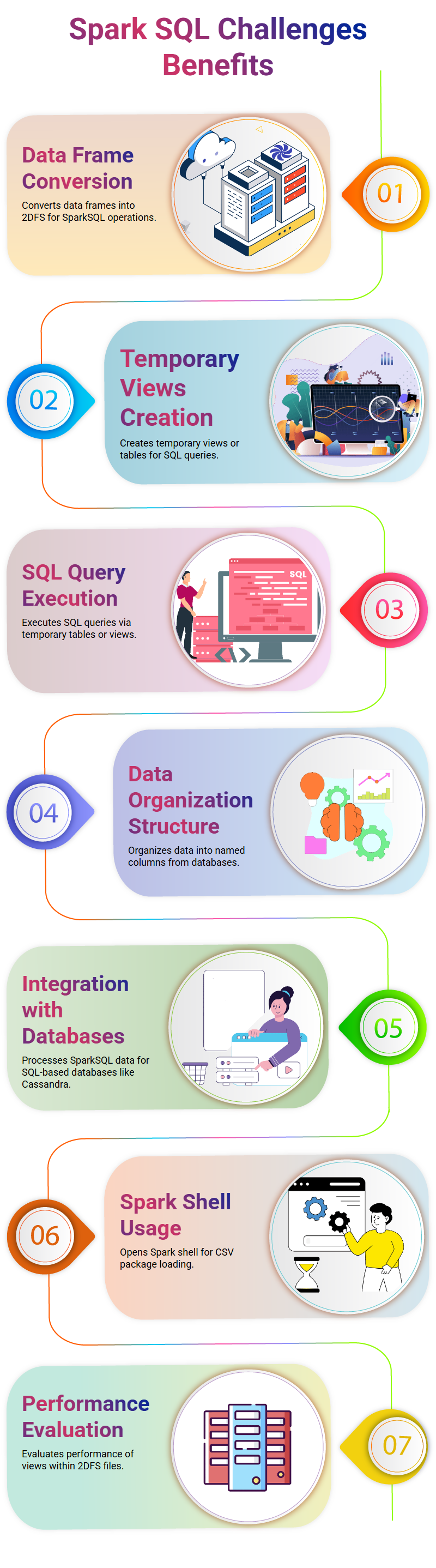
Spark SQL presents us with the challenge of performing any SQL query without directly accessing its original data frame, instead we must create temporary tables or views identical to its original one and write or replace statements to execute all Temporary view or table queries.
Data Organization
Data is organized into named columns to create an illusion of order. This data comes from relational databases.
Data processing occurs using SparkSQL before being imported to an SQL-based database like Cassandra. To open the Spark shell and load competitive X Spark CSV packages into it. “Open spark” opens it first then loads them using “load package”.
Spark can create an EMP data frame
Process involves loading an EMP dot file and creating a data frame using Spark library, before displaying in its schema format which Spark automatically understands.
Schemas provide options such as ID integer, Name string and Fields which make up several options in schema representation of data frames.
Users are then presented with an entire dataset in data frame format for exploration and operations such as filtering dot filters or selecting specific departments.
Spark makes creating data frames both complex and time consuming; however, its advantages include improved performance and flexibility when handling large datasets.
Apache Hive
Apache Hive is an innovative database management system, offering developers access to writing SQL queries that will then be translated into MapReduce jobs resulting in slower performance than its competitor systems such as MySQL or MSSQL.
Apache Hive can present several challenges when handling smaller datasets – particularly those less than 200GB in size – leading to performance issues such as no resume capability and stuck systems; difficulties starting or restarting Hive; as well as not allowing dropping encrypted databases which presents additional security concerns.
Spark SQL has successfully overcome many of its issues and can run faster with MapReduce.
Spark SQL excels over Hive due to its in-memory computation abilities, enabling it to process data directly in memory and complete queries in under one minute compared to Hive’s 10-minute query performance.
Spark SQL offers several distinct advantages over Hive, including faster performance, enhanced data management and greater data storage capacities.

Spark SQL Online Training
Hive Meta Store for Spark SQL
Spark SQL takes full advantage of Hive’s metastore services to query data stored and managed by Hive, making query creation and management efficient and timely.
All Spark SQL-generated tables or queries can also be stored directly within Hive’s megastore allowing faster execution time while improving efficiency.
Spark SQL relies heavily on computation for faster results, with computation taking place entirely within memory reducing storage requirements and speed.
The performance of Spark SQL compared to Hado
Spark SQL’s performance compares favorably with Hado. One feature unique to Spark SQL is its ability to establish connections using simple, JDBC or ODBC Drivers allowing users to connect to Spark SQL using all three drivers simultaneously.
Users may create user-defined functions (UDF) if no function exists to fill their need, while UDF (Understanding Data Functions) allow for execution of unavailable functions.
Spark SQL offers additional features, including user-defined functions that allow for greater customization when standard functions become unavailable, helping users create customized functions more quickly while improving calculations more efficiently.
Data Frames
Data Frames are structured databases designed to store and process structured and unstructured data using SQL queries, to convert raw information into formats which can then be processed using various APIs such as Data Frame DSL or Spark SQL.
Data frames store columns from all data nodes, including worker notes, column details and row details. They’re then converted into data frames using APIs such as DataFrameDSL or Spark SQL for easy storage and processing.
The Data Source API reads and stores structured and unstructured data into SQL databases while Data Frame API reads and stores it directly into an SQL table.
Data frames are essential in managing and processing structured and unstructured data in SQL databases efficiently and provide a centralised platform for accessing and processing it. Understanding various types of data frames as well as their applications for effective data management and analysis.

Spark SQL Course Price

Sai Susmitha
Author
The Journey of Personal Development is a Continuous path of learning and growth.