How FHIR HL7 Improves Patient Data Retrieval
Patient Data in FHIR HL7
FHIR HL7 allows us to query patient records efficiently. In searching, identifications provided by systems serve as keys, including details regarding the system as well as ID values, which further ensure accurate retrieval.
An effective patient search begins with a comprehensive query designed to narrow results to those that truly matter. Apollo Hospital Data allows specific URLs to be used to access patient records that match specific predetermined criteria.
FHIR HL7 enables medical practitioners to efficiently search for patients using reference attributes, such as subject identifiers. This technique also makes retrieving observations related to specific patients more manageable, enabling medical practitioners to gain a deeper
insight.
The implementation of FHIR HL7 API chaining enables healthcare applications to quickly access vital data by streamlining data extraction. This enhances interoperability while expanding the healthcare data ecosystem.
FHIR HL7 APIs for Data Retrieval
Basic FHIR HL7 APIs provide simple querying methods, while more sophisticated APIs offer additional functions, such as directly connecting observation resources with their respective IDs for enhanced data accessibility.
FHIR HL7 chaining is an essential concept, enabling queries based on referenced attributes. When retrieving observation resources, observation identifiers serve as entry points leading to pertinent patient data.
FHIR HL7 Observation Resources
Let’s delve deeper into FHIR and HL7 to gain a better understanding of how we access observation resources. When querying patient information, many wonder whether or not observation resources will appear instead. Thankfully, when searching observation data associated with patients, we do receive observation resources!
So, if I click “send,” I may receive either one or multiple observation resources related to subject ID 400. When scrolling through my list of observation resources for verification purposes, it was exactly as expected.
No intention was intended to mislead; by opening patient data, I can quickly and reliably confirm whether a resource exists. When querying the FHIR HL7 server with a patient identifier as a read operation, I perform the read operation, with some minor typographical errors occurring; however, the overall structure remains intact.
Patient-Specific Observations in FHIR HL7
My API utilises chaining parameters for more refined search results. FHIR HL7 systems return all pertinent observations associated with an individual patient when retrieving observational data. For instance, if medical record identification occurs, FHIR supplies resources accordingly.
This system would locate an observation resource for body height. Should additional observations become available, this system would deliver them simultaneously to ensure quick access via the FHIR HL7 framework, thereby guaranteeing that all vital data remains readily accessible in this approach.
FHIR HL7 prioritises searching for specific observations by applying additional parameters. For instance, to quickly narrow results to only those related to respiratory rate observations, you could add their code, as this ensures only relevant data reaches FHIR servers.
FHIR HL7 Maturity Model
FHIR HL7 maturity model! If you have ever wondered how FHIR HL7 resources evolve, let’s explore together how these resources mature with time.
FHIR HL7 introduces maturity levels through the FHIR Maturity Model (FMM). When new versions of FHIR HL7 are released, resources included within them may or may not have an immediate maturity designation. As implementation occurs, these resources gradually receive maturity designation values over time.
FHIR HL7 Maturity Levels
What exactly do these numbers indicate? Maturity level 0 indicates a resource has been published but remains unsuitable for implementation at basic implementation levels. To move up one maturity level, its responsible workgroup must verify its completion before moving up to level 1.
Every level is built upon its predecessor. At FMM 2, resources should have completed real-world deployments to increase trust. At FMM 3, they become even more robust with increased adoption and reliability across FHIR/HL7 healthcare systems.
Patient Demographics in FHIR HL7
Demographic mapping with FHIR HL7 requires selecting an appropriate resource (‘Patient’ in this example) and understanding its attributes, which helps structure data correctly according to healthcare standards.
FHIR HL7 facilitates the exchange of demographic attributes, such as name, gender, and race, to enable seamless data mapping processes that enhance systems’ ability to categorise and store patient records efficiently.
Data Representation Formats in FHIR HL7
FHIR HL7 supports multiple formats — XML, JSON, and Turtle — but healthcare applications usually prefer JSON due to its ease of parsing.
FHIR and HL7 implementations typically utilise JSON as it provides efficient data transmission. Although structured formats such as XML do exist, they often impose rigid, predetermined schemas, making JSON more adaptable than its alternatives.

HL 7 Training
FHIR HL7 Message Specifications
As developers working with applications that use HL7 V2 as their data transmission protocol, being aware of how to modify message segments efficiently is of immense importance. We frequently develop interfaces using Rhapsody, .NET, or Java code, which must pass tests under both positive and negative circumstances. Making adjustments to an HL7 message requires knowing how to modify fields, components, and subcomponents efficiently.
Let’s first examine how FHIR HL7 messages are structured. Messages typically consist of logical groupings of segment pairs with segment ID as an essential identifier, usually three characters separated by field separators like pipe symbols to organize messages properly.
PID segments (which deal with patient demographics) begin with an ID. Each data element within these segments adheres to a structured format, enabling interoperability among healthcare systems and ensuring accurate representation and compliance with established standards. By adhering to FHIR HL7 specifications, developers ensure an accurate representation and comply with regulations.
Digit Scheme in FHIR HL7
FHIR HL7‘s Check Digit Scheme helps ensure data integrity by checking that entered identifiers comply with predefined standards. A three-character validation step provides extra assurance.
FHIR HL7 utilises hierarchical designator (HD) data types to maintain an audit trail of assigning authorities, providing hospitals with a valuable feature for creating patient records efficiently and enhancing data retrieval.
Name Space ID and Universal Identifiers in FHIR HL7
FHIR HL7’s Name Space ID serves a vital purpose: It acts as an identifiable code for each hospital to facilitate smooth patient record sharing between medical facilities.
As soon as a hospital registers on **hl7.org**, it receives its unique organizational ID that forms part of FHIR HL7’s universal ID process.
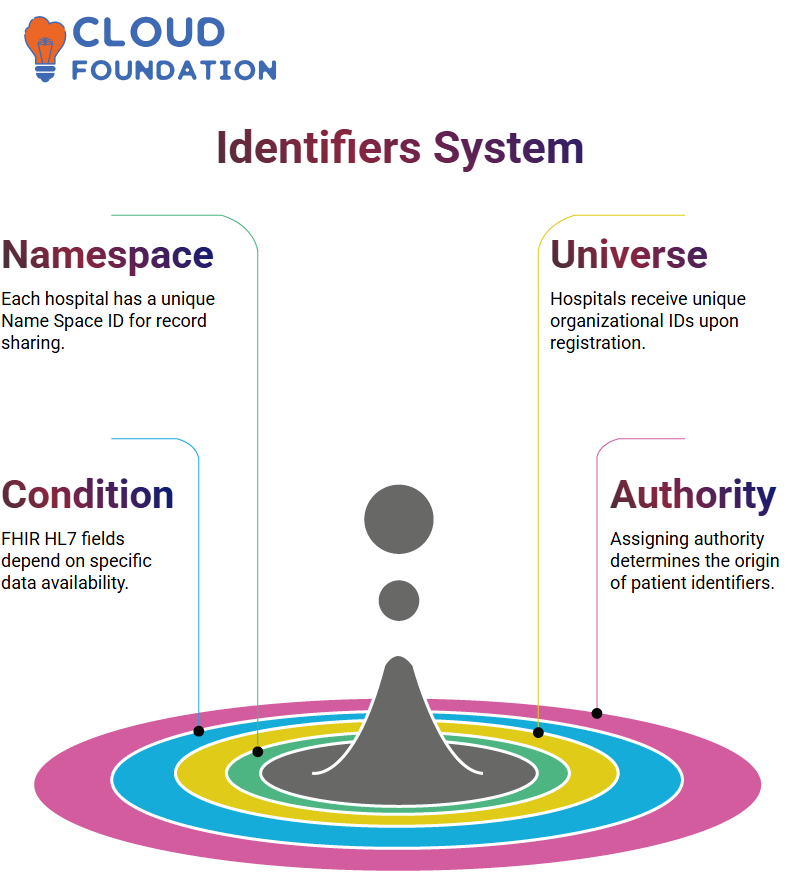
Conditional Fields and Assigning Authorities in FHIR HL7
FHIR HL7 features conditional fields that rely on specific data availability; assigning authority is therefore central in determining where patient identifiers originate. For example, Good Health Hospital could utilise
The individual’s **mRNA codes as patient identifiers within the FHIR HL7 system.
Multiple Patient Identifiers in FHIR HL7
FHIR HL7 provides hospitals with an efficient means to maintain multiple identity records for one patient at a time. A facility may store identity codes across different sections to preserve historical continuity.
Legacy hospitals switching from HL7 2.1 to 2.6 must ensure backwards compatibility to ensure seamless integration without disrupting existing systems.

HL7 Tables and Data Types
FHIR HL7 provides predefined tables that store values essential to healthcare interoperability, enabling applications to communicate seamlessly across various healthcare environments. By maintaining uniform representation across these tables, FHIR HL7 helps facilitate application communications more seamlessly than ever.
Understanding how HL7 tables operate can assist in selecting which values to utilise; some tables provide general references rather than setting strict values, encouraging users to consult relevant documentation for guidance.
Handling Patient Information in FHIR HL7
FHIR HL7 patient information follows an industry-standard format. Hospitals may create customisations for administrative details to maintain consistency across systems.
Gender representation within HL7 utilises single-character codes, such as M, F, and T, for male, female, and transgender individuals, respectively, enabling seamless data exchange across applications.
FHIR HL7 in Data Representation: JSON vs XML
FHIR HL7 resources can be organised using either JSON or XML formats; however, JSON remains more popular due to its readability and ease of integration into applications.
JSON employs key-value pairs to define attributes in a structured and easy-to-understand format; FHIR HL7 resources utilise it, allowing applications to parse it with ease.
JSON offers developers an easier alternative than XML by eliminating complex schemas, making FHIR HL7 development effortless, and streamlining healthcare interoperability. Adopting JSON into FHIR HL7 ensures interoperability among healthcare systems worldwide.

HL 7 Online Training
FHIR HL7 in Healthcare Systems
FHIR HL7 provides structured examples to help newcomers understand its implementation. using JSON-based models can significantly increase data accuracy and usability for healthcare applications.
Proper implementation of FHIR HL7 ensures that all attributes, including flags for modifications, are processed correctly by applications, enabling improved decision-making and reducing misinterpretations of patient records.
Developers working on healthcare solutions require an in-depth knowledge of FHIR HL7 data structures as the cornerstone for effective information collection and use. This knowledge ensures maximum information capture.
Employee Contact Data with FHIR HL7
Imagine we’re using FHIR HL7 data for multiple employees at a telecom company; each employee’s information must be organised systematically. With JSON, we achieve this by using arrays of objects that contain unique employee profiles.
FHIR HL7 supports structured data formats that simplify repeating telecom details across employee records in an organised fashion. Instead of duplicating fields within objects, our applications use array structures for efficient data management through FHIR HL7-based applications.
Telecom Data for FHIR HL7 Integration
Data integrity is of critical importance in FHIR HL7 implementations, especially when handling telecom numbers. To ensure accurate mapping and compatibility across systems that adhere to FHIR HL7 standards, telecom fields should be structured consistently within JSON files to prevent parsing errors and provide correct mappings.
Structured arrays in JSON provide greater flexibility when storing multiple phone numbers. A well-formed JSON structure also facilitates reliable data handling within FHIR HL7 applications by organising telecom details as objects within an array. By organising telecom details this way, data models that adhere to FHIR HL7 best practices can be created more easily and flexibly.
FHIR HL7 Profiling
Profiling is a fundamental concept within FHIR HL7 specifications; think of it like tailoring base profiles to suit specific requirements. in FHIR HL7, patient resources have default structures; sometimes, additional restrictions must be added, and therefore, profiling is crucially important.
To make gender an integral part of the field, we can customise its structure definition profile accordingly and require that its presence always remains across applications using FHIR HL7. This ensures consistency among applications while still meeting our goal of maintaining consistent user experiences across FHIR HL7 applications.
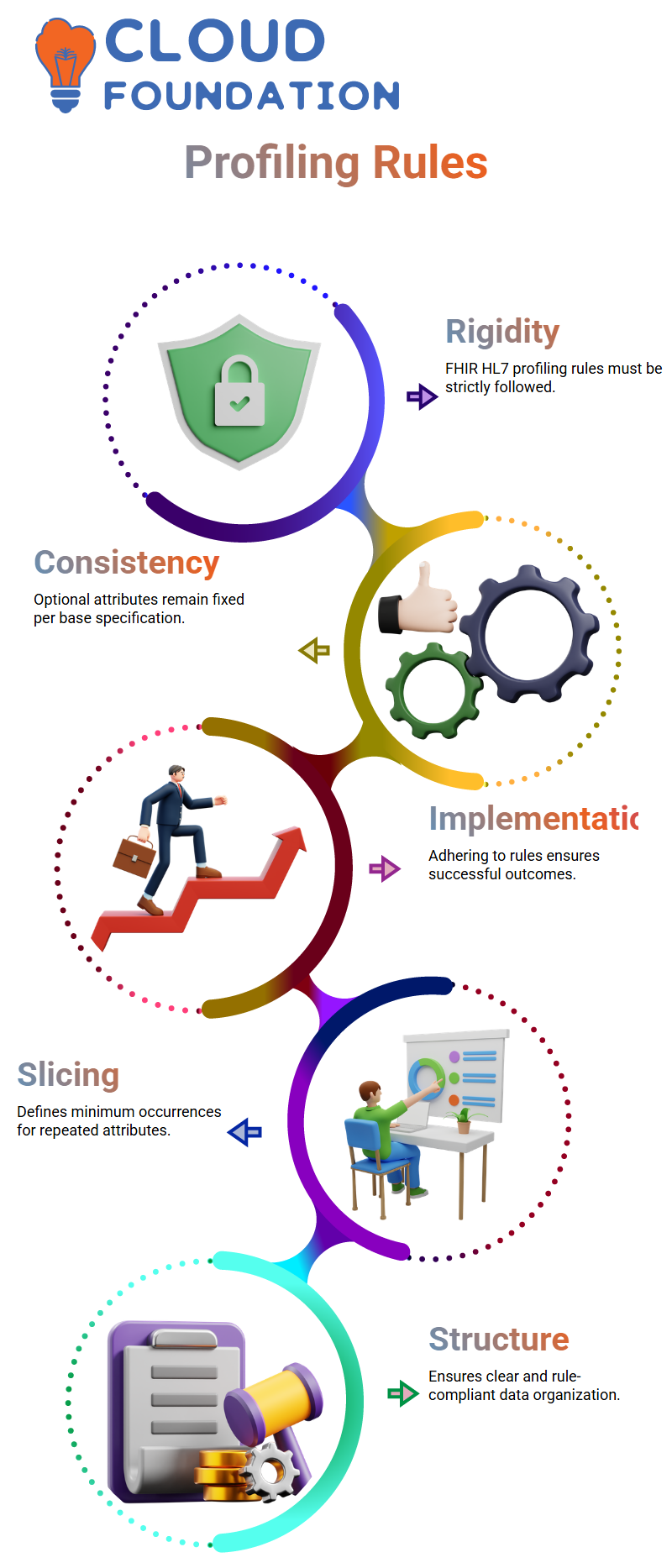
Rules for Profiling in FHIR HL7
FHIR HL7’s profiling rules are rigid; adding or subtracting attributes arbitrarily cannot occur randomly or arbitrarily, while optional attributes must remain fixed per base specification to facilitate smooth implementation and ensure successful outcomes. Knowing and adhering to them makes implementation simpler.
Slicing in FHIR HL7
Have you noticed repeated attributes in FHIR HL7? Slicing can help define minimum occurrences for attributes such as phone numbers or email addresses, making data structures more straightforward while adhering to established rules in FHIR HL7.
FHIR HL7 Specifications
FHIR HL7 is an industry-standard healthcare framework that details how patient data must be organised, exchanged, and processed. If you can understand one specification, then any will do; its fundamental principles remain constant.
FHIR HL7 provides structured formats for reading patient information, including tabular formats, UML diagrams, XML files, JSON data streams, and Turtle formats. Understanding these systems enables seamless integration of data into healthcare systems.
Queries in FHIR HL7
FHIR HL7 enables the narrowing of queries for more efficient results, allowing the use of multiple observation codes or filters to retrieve only essential data.
Rather than retrieving all observations at once, we can focus on retrieving those that fall within specific parameters or observation codes.
Imagine this: when an observation includes blood pressure, body temperature, and heart rate measurements on one patient, using FHIR HL7 query restrictions can limit our request to only heart rate observations, thereby eliminating unnecessary data retrieval.
Utilise these techniques to simplify working with FHIR HL7. By structuring queries efficiently and leveraging system features such as subqueries to retrieve patient information without extraneous details that do not pertain directly, efficiency increases significantly, and accurate patient records are obtained without unnecessary details.

HL 7 Course Price

Navya Chandrika
Author