Best MuleSoft MUnit Testing Training Online
Cloud Security in MuleSoft
Security is always a primary concern when working with MuleSoft , especially when credentials or external system passwords change, as they often override values directly within the cloud.
Theminor updates, you won’t have to redeploy everything. MuleSoft typically requires the IP addresses of workers to establish connections.
 If you are uncertain whether your system requires allowing specific IPs, advise verifying early. Trust me; doing this could save hours of debugging.
If you are uncertain whether your system requires allowing specific IPs, advise verifying early. Trust me; doing this could save hours of debugging.
Features of MuleSoft MUnit
MuleSoft MUnit makes testing Java-like apps efficient and straightforward. Built upon Java and Spring concepts, MuleSoft extends its strength further by including MUnit into its arsenal; you can write test cases just as if they were written directly for Java-coded apps.
MUnit works reactively – your flows react to events by listening for events and processing messages with attributes and exceptions as soon as they arrive; in effect, creating an internal publisher/subscriber model connected by smart connectors.
Connectors in MuleSoft allow your apps to interact with external systems, such as Salesforce, SAP, or HTTP endpoints.
When developing apps with MuleSoft, connectors must be marked so that MUnit can perform appropriate tests. This allows flows based on contracts to be tested without impacting live systems.
MuleSoft MUnit Testing
MuleSoft tests help ensure you remain on course without hastening through test cases. MUnit supports mock payloads to confirm they meet the expected conditions, helping to detect issues early.
As part of developing your skills, write multiple test cases simultaneously and run them. MuleSoft provides debug links and interactive tools, allowing you to experiment with various testing methodologies and concepts.
How does MUnit help with mocking in MuleSoft?
Mocking plays a crucial role in MuleSoft testing. Before and after running code, MUnit allows users to validate behaviour with assertions, mocks and custom verifications; tools like “set event,” “set null payload”, and SQL commands enable testing teams to simulate and control tests effectively.
MuleSoft enables you to define complex data types, such as employee objects with details like date of birth or city PIN code, to accurately mock API inputs and test private flows, or simulate POST requests with ease.
What are the key tools available for API testing in MuleSoft?
MuleSoft makes testing at an API level easy by offering mock connectors internally that simulate request/response cycles.
For instance, if your API uses two-way SSL connections and cannot always communicate with external systems, MUnit fills the gap by simulating these interactions and generating request responses.
API Kit Console and Postman provide tools that simplify API testing, while MuleSoft accelerates testing even further with its auto-discovery of endpoints for even faster testing.
MuleSoft app locally, run it, and check its behaviour with any tool without hassle or distractions.
MuleSoft Mock Connectors
Mock connectors often send logs or trigger unexpected actions without user intervention; one such instance was when an employee was created without consent due to a misconfiguration in a mock connector.
Keeping an eye on test logs can help identify these problems early and ensure a seamless testing experience.
Debugging and Breakpoints in MuleSoft
Debugging MuleSoft can be challenging, especially when using breakpoints.
The troubleshooter identified why an asset in RAML Spike wasn’t behaving correctly, only to realise that it wasn’t valid as an entity and therefore couldn’t be treated as such.
 MuleSoft immediately flagged that it was creating multiple matches incorrectly by calling store procedures directly without verifying they existed first, leading to the “get actor does not exist” error message.
MuleSoft immediately flagged that it was creating multiple matches incorrectly by calling store procedures directly without verifying they existed first, leading to the “get actor does not exist” error message.
How MuleSoft Debugging Helps Fix Errors Quickly?
Anypoint Studio simplifies debugging MuleSoft applications by allowing you to stop at breakpoints to determine the necessary headers, destinations, and parameters to advance the flow.
In these situations, headers, destinations, and parameters must be set correctly to prevent blocking further advancement of the flow in MuleSoft apps.
Setting the JSON payload correctly after consumer operations can make a critical difference when debugging MuleSoft; any small error here could cause errors to arise or return bad requests from your app.
When debugging in MuleSoft, as any miscalculation here could potentially cause errors or return incorrect requests that lead to app failures or errors within MuleSoft itself.

MuleSoft Training
How do payloads and XML play a role in MuleSoft debugging?
MuleSoft’s payload acts as the primary data carrier during flow execution. You may notice that its value is zero or empty at breakpoints during debugging – this is perfectly normal until it’s set correctly.
Knowing when and how MuleSoft updates the payload during your flow may help you diagnose potential issues more quickly that may arise during execution.
MuleSoft often deals with XML transformation. When switching formats, use curly braces correctly in Data Weave expressions to avoid syntax errors and enable MuleSoft to handle XML data smoothly.
Logging and Variable Access in MuleSoft Flows
Logging is a crucial aspect of MuleSoft projects. Your main flow and child flows will need to know which variables and payloads can be found at different points to get an accurate picture of what is accessible at various moments.
MuleSoft makes query parameters and payloads available in its main flow; they may only become accessible in child flows when their process returns.
Understanding this fact enables you to write more effective logs quickly while resolving data-related issues more efficiently.
MuleSoft in Practice: Real Challenges and Real Fixes
Whether it’s encrypting passwords, fixing environmental issues, or managing workspace tokens, every step teaches something valuable about yourself and the rest of humanity.
One of our team developers recently encountered difficulty when copying a command. Instead of spending their valuable time fussing around with it, they cloned their code from GitHub and continued.

Additionally, we found that not every processor supports Anypoint Studio in the same way. On specific systems, things might break unexpectedly; therefore, we test various machines until one runs MuleSoft seamlessly with JDK 11.
Navigating Early Project Hiccups with MuleSoft
Starting any project can bring both excitement and challenges, something we’ve experienced with our MuleSoft integration project. After successfully running initial MySQL connection tests, our initial MySQL connectivity tests are complete.
As soon as the team began its efforts, some technical challenges arose, with one major roadblock being the inability of some team members to connect to the project environment.
As our success rate in connecting rose to 70-80%, it became apparent that we needed to conduct further investigation into this matter.
We shared resources on WhatsApp and distributed PDF documents as aids for debugging purposes. While success rates may have reached 70-80%, further work would be needed before moving forward with resolving our problems.
Communication Barriers in MuleSoft Projects
At MuleSoft group meetings, we experienced some strange muting issues. A participant remained muted despite our attempts to make them hosts; nonetheless, their problem persisted.
Many have encountered a similar dilemma: they have been muted and are unable to hear any sound. We are simultaneously trying to import an entire MuleSoft project.
As it happened, this event served as a stark reminder that even minor communications issues can significantly impede progress when working collaboratively on collaborative platforms like MuleSoft.
These miscommunications also underscore the importance of fast and efficient MuleSoft development processes, based on clear dialogue.
Key MuleSoft Details to Remember
One of the key pieces of advice we can share with MuleSoft users is to pay close attention to details that matter.
This includes securing properties, setting up appropriate IP allowlisting rules, and understanding the types of payloads that can be sent.
These details make a significant difference both during real projects and the maintenance exam process.
MuleSoft JMS and Queues
As you gain experience using MuleSoft, one of the key concepts you’ll encounter is Java Messaging Service (JMS) and how it integrates with MuleSoft queues, such as VMQs or ActiveMQ.
MuleSoft JMS plays a crucial role in supporting high-demand applications that must process a large volume of requests reliably and seamlessly.
When your app encounters an overwhelming surge of requests, MuleSoft JMS quickly steps in with queues based on order and timing to hold these requests for processing later. Thus, ensuring no data gets lost and requests can be handled efficiently.
Key JMS Operations in MuleSoft
MuleSoft employs four primary JMS operations for handling messages: VM consume, VM listener, publish and consume. Each plays its own role:
VM consume lets your app consume messages anywhere within a queue by providing only its name as input.
VM listener listens actively for requests arriving for delivery immediately, whilst *Publish sends them immediately out, whilst
Consume gathers them all back up from the flow’s start point. Understanding these operations is crucial for optimising MuleSoft apps and ensuring message security and reliability.

MuleSoft Online Training
MuleSoft VMQs: Persistence and Transience
MuleSoft VM queues offer you two choices for transient or persistent messaging: transient queues are designed to delete messages when an application goes down; on the other hand, persistent queues hold onto messages until they’ve been consumed.
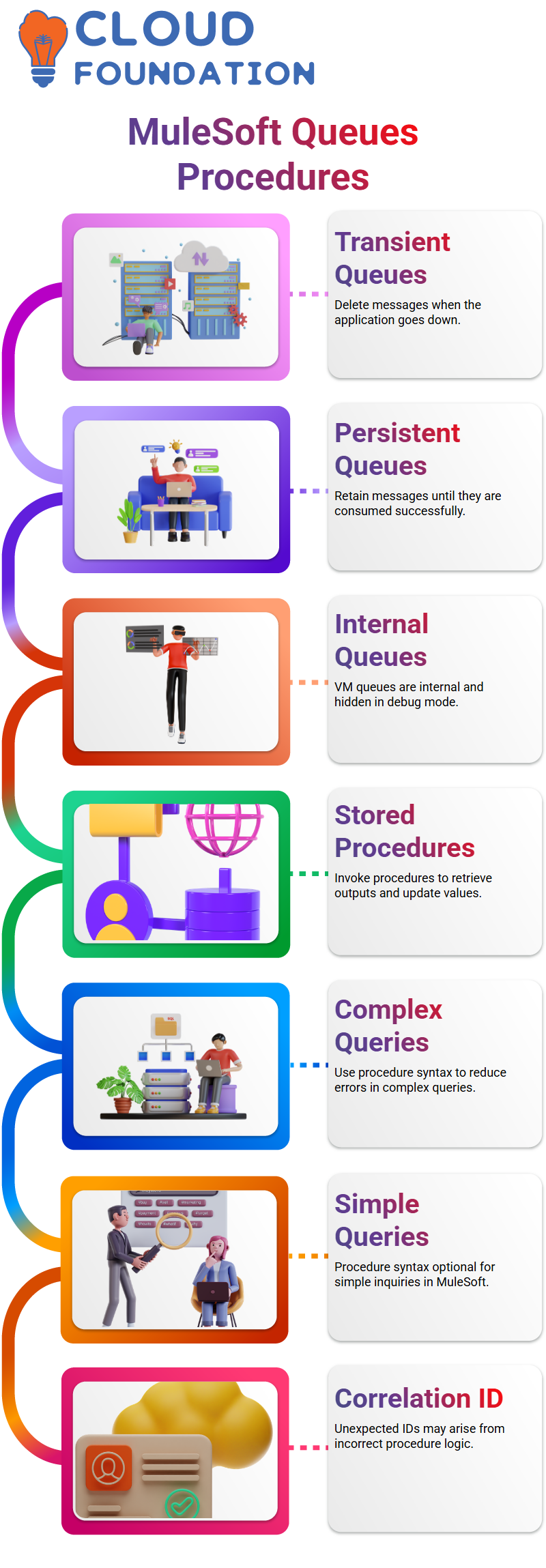
This feature ensures that no message goes undelivered. Note that MuleSoft VM queues are internal and not visible in debug mode; therefore, understanding their behaviour is key to troubleshooting them effectively.
Sakila Detector and Store Procedure Results in MuleSoft
MuleSoft enabled me to invoke this stored procedure method and retrieve its output, which was later used to update counts or values.
MuleSoft recommends using stored procedure syntax when performing complex queries to minimise unexpected errors and ensure success.
Although store procedure syntax isn’t strictly necessary for simple inquiries, using it could prevent unintended outcomes that cause unexpected complications or miscalculations.
One issue encountered involved an unexpected correlation ID being automatically generated from its ID, something MuleSoft typically does not do. This odd behaviour stemmed from incorrect or unknown procedure logic.
Sub-flows vs. Sync Flows in MuleSoft
MuleSoft allows me to explore the differences between Sub-flows and sync flows. Sub-flows do not include error handling by default, whereas sync flows do, making sync flows my go-to choice when building stable, fault-tolerant applications.
To gain access to our MuleSoft APIs, send the request through an endpoint exchange using client credentials, and then request access through the API portal.
After ensuring everything works as expected, request access again through the API portal and verify that all functions operate as expected.
Why MuleSoft Duplicates Data for E360?
MuleSoft E360 requires an understanding of why data is duplicated across tables, for instance, when we use customer tables in provisioning tools or views.
MuleSoft intentionally uses redundancies, as this provides E360 with access to more central hubs for manipulating the information it holds.
MuleSoft utilises this hub as the foundation for all its operations; provisioning tools rely on it when creating business entity views, building layouts, and designing user interfaces.
Handling Lookup Fields in MuleSoft
Lookup objects with “yes” as their lookup indicator should create both reference entities and business entities for optimal performance.
When there are more than 3,000 records to process, this strategy is absolutely required; otherwise, one type tends to be preferred over the other.
Mapping and Relationships in MuleSoft Business Entities
MuleSoft excels at managing complex relationships. Utilise business entity views for role type manipulation and deriving attributes; often these views mirror their counterparts’ structure without system attributes attached.
Think of these relationships like trees: one-to-many or one-to-one between parent and child entities.
MuleSoft makes mapping data between views and entities straightforward by offering one-to-one mappings between Business Entity (BE) Views and base objects.
When we need to retrieve or update information in an entity, this transformation ensures everything remains synchronised and accurate.
MuleSoft Cleanse Functions in the Hub
MuleSoft’s MDM environment features two types of transformations: direct and cleansing.
Direct transformations help with standardisation or derivation processes, while cleanse functions act as pass-throughs suited for validation steps.
MuleSoft on Windows 11
At first, setting up MuleSoft may seem complex. Juggling multiple tools, such as Java, Apache Maven, and Anypoint Studio, might seem challenging, but once done a couple of times, it becomes second nature.
First, download Apache Maven from the Google website. Although optional, having it installed can make your MuleSoft experience smoother and quicker. Immediately upon downloading it, set the path environment variable on a Windows 11 system accordingly.
As soon as that was over, however, something wasn’t right. Maven wasn’t correctly detecting the version. After some investigation, we realised this might have been caused by not installing Java yet (an obvious error!), so we went back and installed JDK 10.4 alongside setting JAVA_HOME accordingly.
Always double-check environment variables. MuleSoft relies on them being correctly configured.

MuleSoft Course Price

Vinitha Indhukuri
Author