AWS DynamoDB Tutorial
What is Amazon Dynamo DB
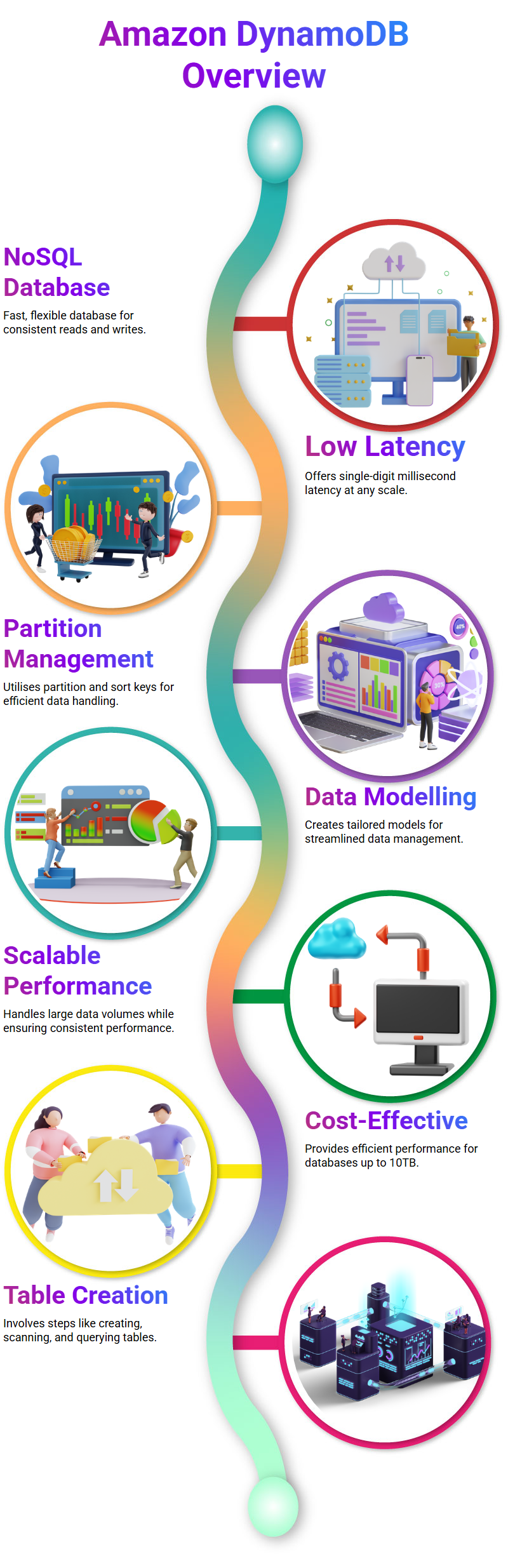
Amazon DynamoDB is an affordable NoSQL database service tailored for applications that demand reliable data storage.
Offering single-digit millisecond latency at any scale, DynamoDB makes an excellent solution for applications needing consistent information – especially mobile web gaming applications.
DynamoDB is an indispensable resource for managing and organizing data within partitions.
Utilizing partition and sort keys to identify entities within tables, DynamoDB ensures that data stored or retrieved accurately from storage or retrieval operations.
DynamoDB helps users effectively organize and store data by utilising key-value pairs for efficient storage of records.
Features of DynamoDB
DynamoDB is an efficient data management solution, helping organisations manage large volumes of information efficiently.
DynamoDB allows users to build more tailored models suited specifically to their requirements using its diverse data types and resources.
DynamoDB data modeling can provide invaluable benefits to organizations by streamlining their data management processes.
DynamoDB can be relatively affordable while offering millisecond latency depending on its size (usually 1-10T of data). Users can effectively model applications by following its five-step approach to creation.
DynamoDB provides an effective means of handling large volumes of data while guaranteeing consistent performance at any scale.
How to create a DynamoDB table
An active DynamoDB table requires several steps, from initial creation through adding records or items and scanning/querying it, followed by regular analysis.
DynamoDB tables require several steps, beginning with creating the orders table and adding records or items.
By default, DynamoDB has set its capacity settings so as to allow for at least five read capacity units and five write capacity units per table created using its default configurations.
Create a DynamoDB table involves several steps, from initial creation of the table through adding records or items and scanning it, until finally analysing its results.
A DynamoDB table should reflect your specific requirements as well as data stored within your database.
What are the key steps involved in modelling data with DynamoDB?
Entity Diagram Maker helps create an entity diagram for your applications to identify key entities for easier mapping between real world entities and those used within your application.
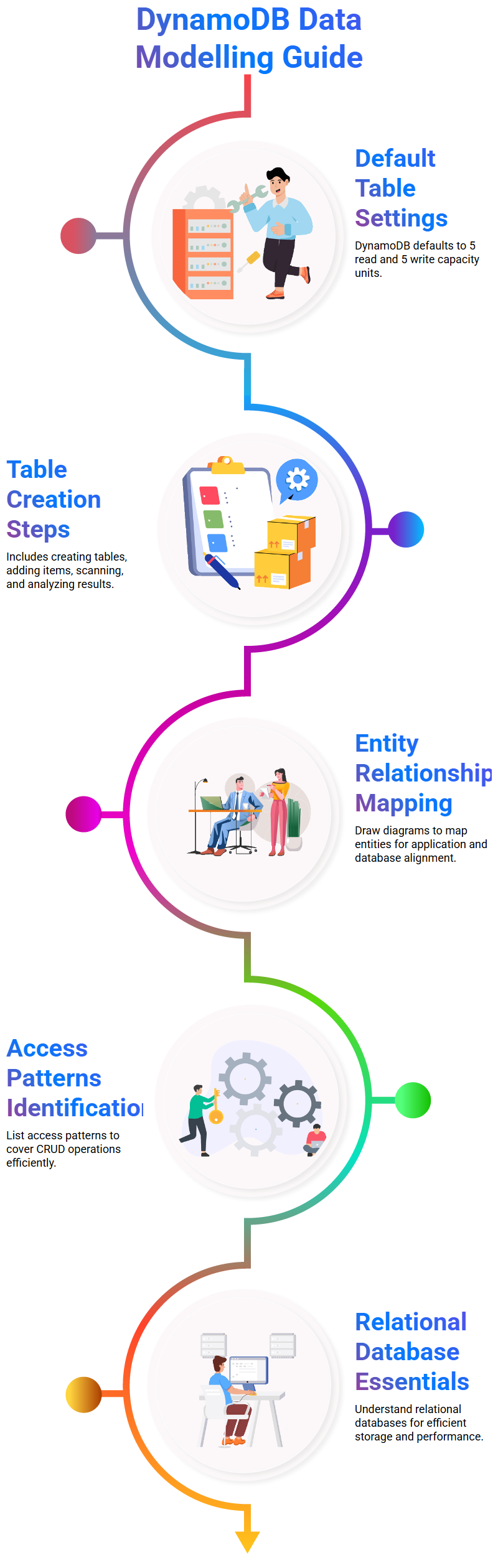
Find relationships among these entities to provide evidence for data modelling. If there are many-to-many relationships between two or more entities, that might offer clues as to their correlation or interaction.
Ascertain all access patterns for each entity. This step is essential as it helps identify all of the access steps needed in your app, from crud operations to filters and primary keys that store data within databases.
Relational databases inDynamoDB
Relational and SQL databases provide effective storage solutions, eliminate redundant information, and increase performance.
Storage costs remain an ever-present worry and understanding the differences between relational and SQL databases is key for effective data management.
Relational and SQL databases both store information about real world entities; each type has specific uses that depend upon certain characteristics or rules that define how data should be organized or displayed.
Relational databases like MySQL, Oracle and Microsoft SQL Server have long been employed.

AWS DynamoDB Training
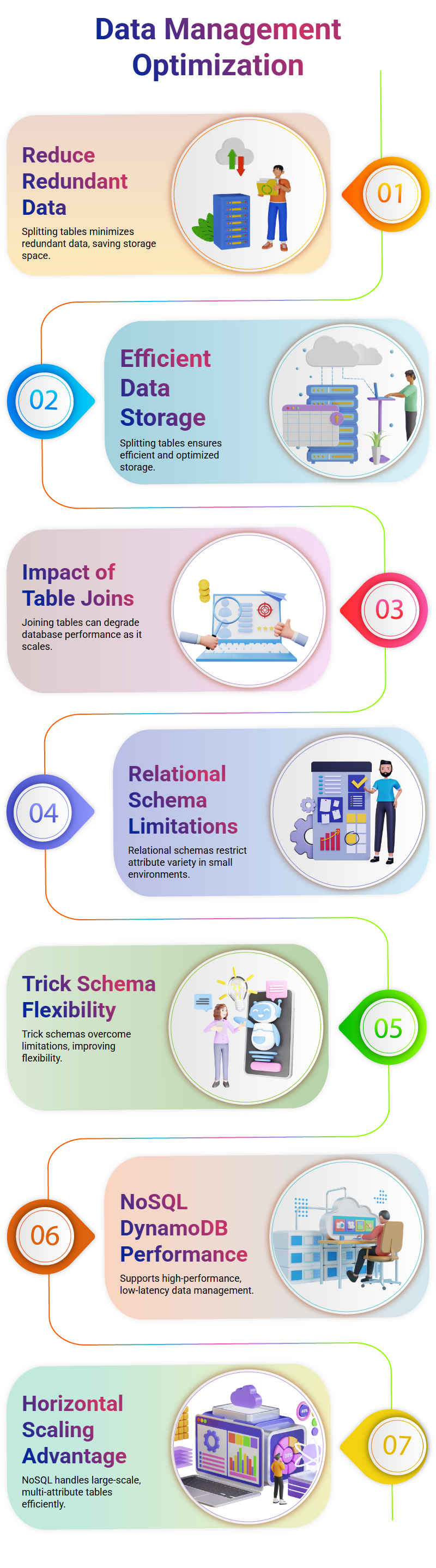
Data Normalisation is a key feature of relational databases that allows them to efficiently store information by breaking it up across various tables for efficient storage purposes.
By eliminating redundant copies of data across tables and thus saving storage costs.
Particularly relevant when working with large amounts of data. Modelling is designed to optimize storage by breaking data across several tables; once this has occurred it becomes necessary to join these tables to retrieve all relevant information.
This process ensures data is stored efficiently, decreasing the need for additional storage space.
Relational databases’ performance can be affected by their table join count which could result in performance decline as their database expands.
Complex queries generated by Relational Management tools often cause significant performance degradations.
Small database environments — like those used for social media applications and big data applications — often adhere to rigid schema rules for maximum data integrity and efficiency.
To combat this challenge, relational databases typically feature strict schema designs in smaller environments like social media.
Trick schemas provide more flexibility by bypassing this restriction and accommodating items with varied attributes in one table.
This schema limits the number of rows with distinct attributes; trick schemas provide ways around it.
NoSQL databases in AWS DynamoDB
Amazon DynamoDB from AWS is a fully managed NoSQL database service intended for high performance applications that need continuous latency of only milliseconds at any size.
Support for document and key-value formats as well as security, backup, and in-memory caching make DynamoDB ideal.
NoSQL databases are designed for computing rather than storage, offering solutions which minimize duplicate copies and reduce computational power required to retrieve information.
NoSQL databases’ primary advantage lies in their capacity for horizontal scaling; thus enabling more efficient retrieval and management.
These systems can easily manage large volumes of data across numerous tables with different attributes; however, this may cause performance issues when dealing with extensive amounts.
The importance of using a front-end filter in a database system
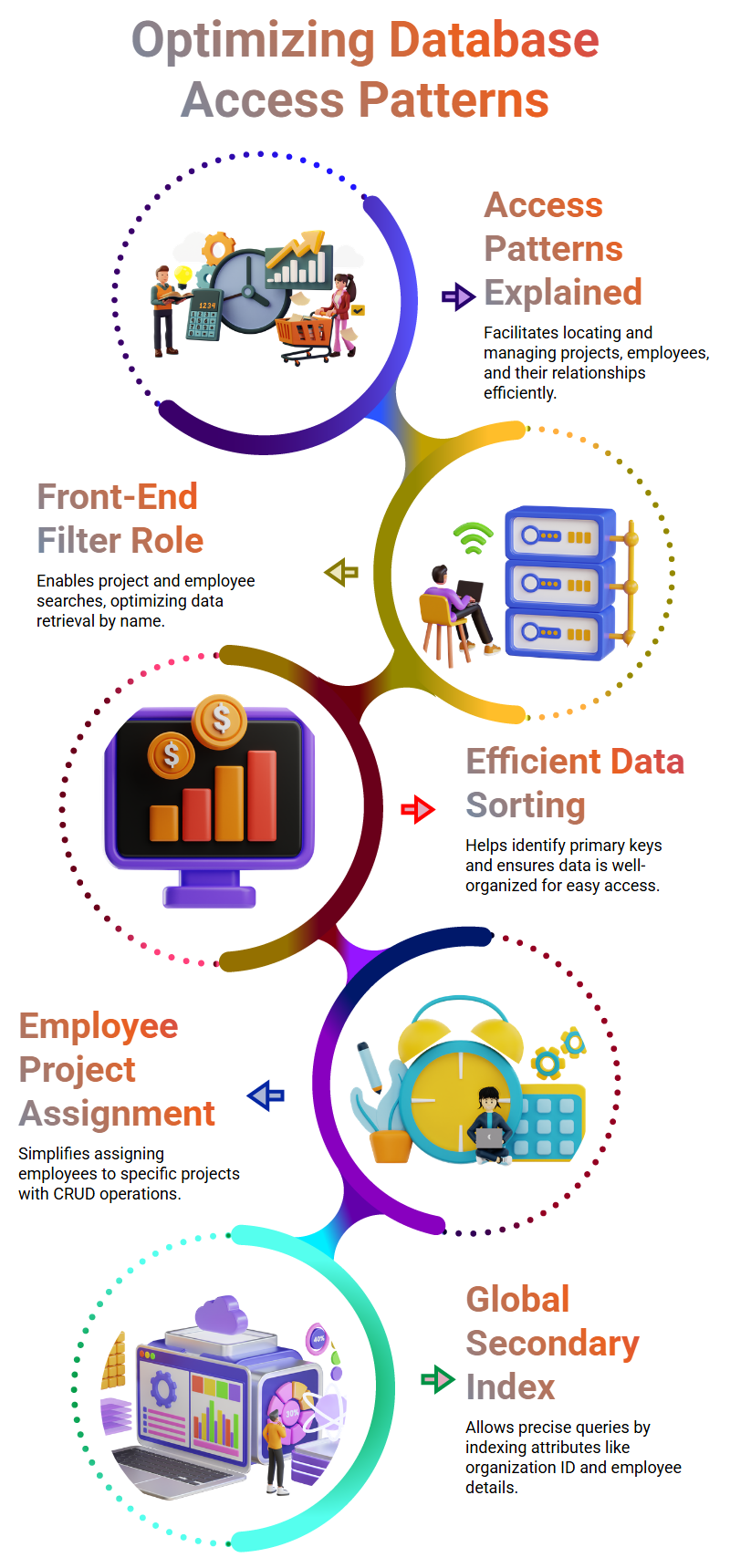
These main access patterns cover organisations transitioning into projects, employees assigned to those projects and on-hold projects.
Their purpose is to help users quickly locate projects by name or employee assignment as well as understand any relationships that might exist between projects and employees.
Access patterns involve assigning employees to specific projects through various operations like create, read, update and delete, as well as create read update and delete operations.
Users are able to quickly locate each project by name, assigned employees and relationship between projects and employees.
Users can quickly search an employee by name using the front-end filter for quick identification of an employee.
This process helps users identify the primary key of their table and ensures their data is efficiently sorted.
Utilising this pattern, employees are assigned specific projects with this being the ideal way of finding project managers responsible.
The fourth key access pattern entails identifying a primary key of any table in question.

AWS DynamoDB Online Training
Global Secondary Indexin DynamoDB
Global secondary indexes provide users with access to a backstage table containing items indexed. A project employee index allows users to quickly locate projects and employees within an organisation.
This Global Search Index’s (GSI) primary key is an Organisation ID followed by their EMP Value (C).
C serves as its own soft key; hence GSI usage includes searching all organizations by name as well as projects or employees by name and organizations by their name.
To overcome these hurdles, GSI overloading was developed. When creating either a global or local GSI index, secondary indexes can be added on an existing table while specific attributes serve as partition keys – each partition key and sort key differing from both its parent table’s partition key and sort keys.
In this example, both partition keys of the table itself (Sword Key of Table), the partition key for Global Space Information Infrastructures (GSIs), as well as their sword keys are utilized. However, only one sword key will be utilized on an GSI.

Access patterns in DynamoDB
Access patterns are another essential aspect of GSI overloading. They allow different kinds of data to be organized within tables for easier querying and management of this massive amount of information.
DynamoDB uses partition and sort keys as its primary access pattern; primary keys serve to identify entities within one table (for instance an application), such as being identified through hashing of partition keys which constitute its primary key (known also as hash or sort keys).
A partition key determines how data should be divided and stored, for instance determining where organisation item data should go (oak hash 1 2 3 for instance).
A hash function determines this partition key to partition specific pieces of information such as organisation items.
Hash functions are used to determine where data should be stored or retrieved and to sort specific items within each partition using range keys (often known as sort keys).
The result of the hash function determines this choice. Afterward, using sort keys as range keys enables specific data items within one partition to be quickly found for retrieval or storage.
Conclusion
Amazon DynamoDB provides an highly scalable and flexible NoSQL database solution designed specifically to support modern applications that need low latency access and high performance.
DynamoDB makes data storage and retrieval efficient with partition and sort keys, making it ideal for applications utilizing complex data models or large datasets.
Designing data models using a five-step process, global secondary indexes and access patterns empowers users to optimize their database in terms of both performance and cost efficiency.
DynamoDB integrates well with other AWS services, including caching and in-memory capabilities, to allow applications to scale seamlessly without impacting speed or reliability.
DynamoDB provides organizations with an efficient means for managing vast quantities of information while still maximizing performance.

AWS DynamoDB Course Price

Vinitha Indhukuri
Author